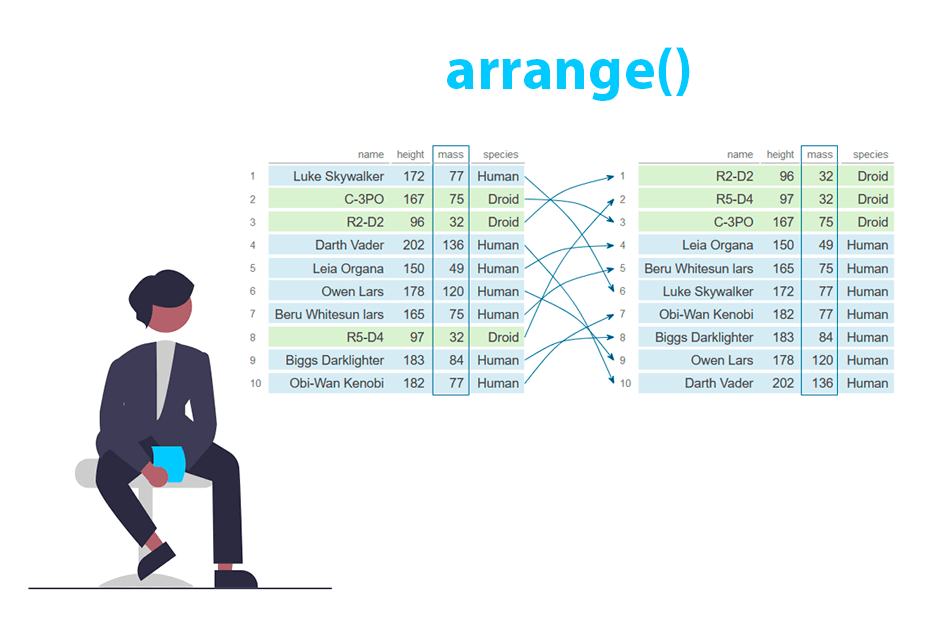
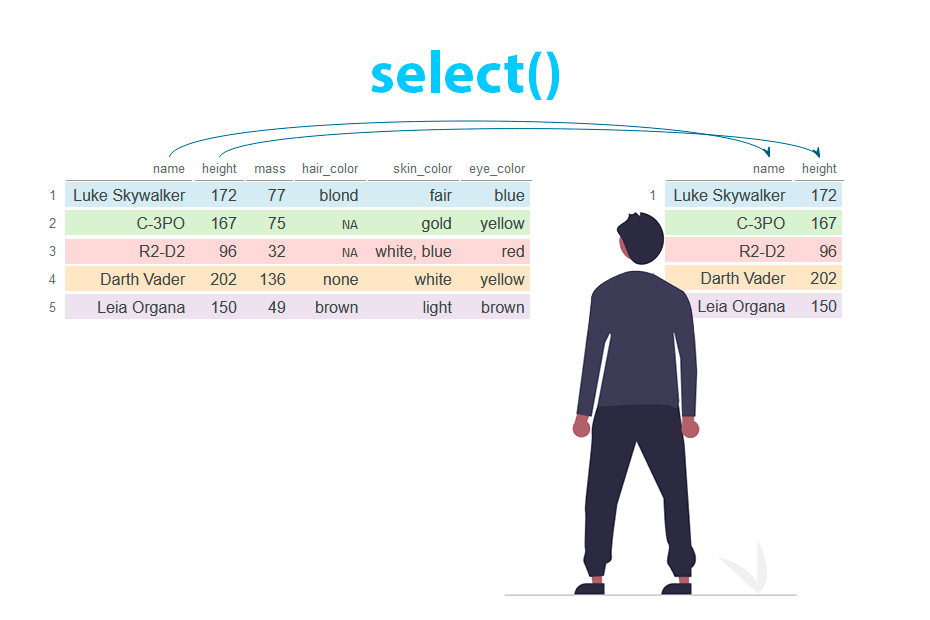
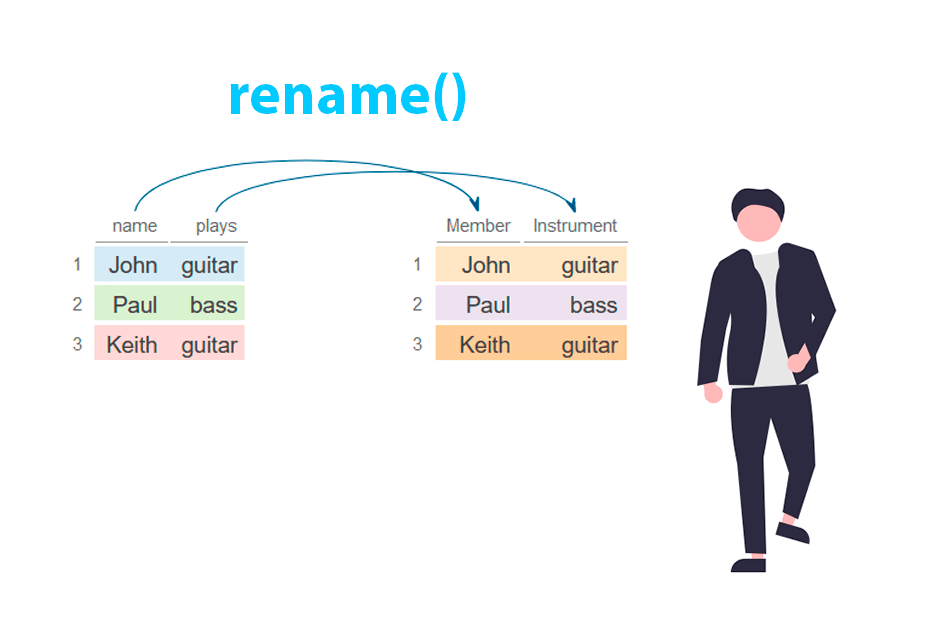
Create and modify columns in R with the mutate() function from dplyr
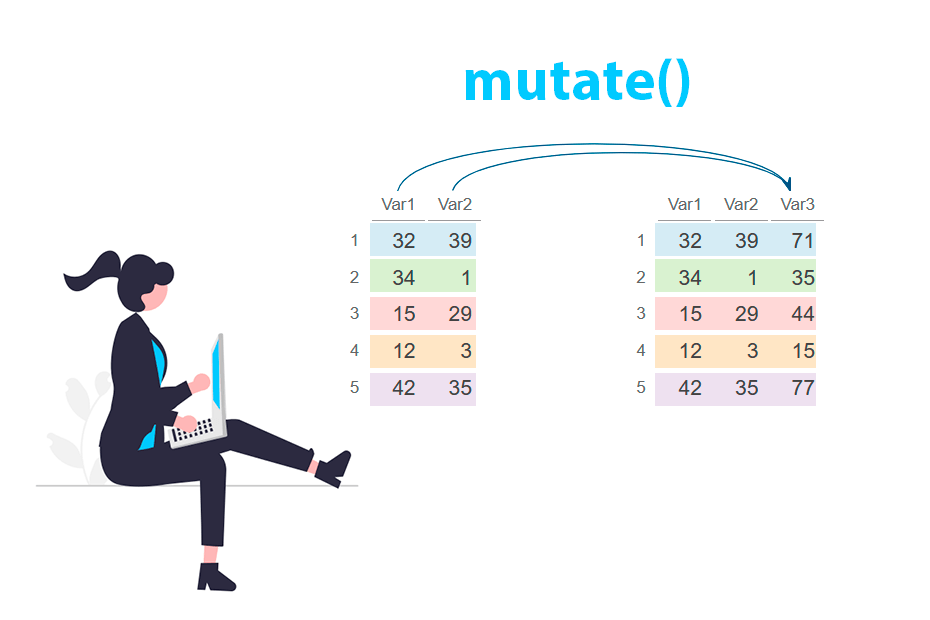
The mutate function from dplyr package is used to create new columns or modify existing columns in a data frame, while retaining the original structure. It enables users to apply functions or operations to data within a data frame and store the results as new variables.
Syntax
The syntax of the mutate function is the following:
# Basic usage
mutate(.data, new_column_name = expression)
mutate(
.data, # Data set
..., # New columns (new_column_name = expression)
.by = NULL, # Grouping variables
.keep = c("all", "used", "unused", "none"), # Which columns to keep
.before = NULL, # New columns will appear before this
.after = NULL # New columns will appear after this
)Create columns
To create a new column you can specify the new column name (Var3) and a expression to calculate the values of the new column. In the example below the expression is the sum of two other columns (Var1 + Var2).
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# New column with the sum of 'Var1' and 'Var2'
df_2 <- df %>%
mutate(Var3 = Var1 + Var2)
df_2 Var1 Var2 Var3
1 32 39 71
2 34 1 35
3 15 29 44
4 12 3 15
5 42 35 77
You can also apply a function to a column to create a new one. The following example illustrates how to create a new column with the square root of another.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# New column with the square root of 'Var1'
df_2 <- df %>%
mutate(Sqrt_Var1 = sqrt(Var1))
df_2 Var1 Var2 Sqrt_Var1
1 32 39 5.656854
2 34 1 5.830952
3 15 29 3.872983
4 12 3 3.464102
5 42 35 6.480741
Add multiple columns at once
Notice that you can add several columns simultaneously by passing more expressions separated by commas to mutate.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Create three new columns named 'Var3', 'Var4' and 'Var5'
df_2 <- df %>%
mutate(Var3 = Var1 + Var2,
Var4 = cumsum(Var1),
Var5 = ifelse(Var1 > Var2, TRUE, FALSE))
df_2 Var1 Var2 Var3 Var4 Var5
1 32 39 71 32 FALSE
2 34 1 35 66 TRUE
3 15 29 44 81 FALSE
4 12 3 15 93 TRUE
5 42 35 77 135 TRUE
Using across
The across function allows to select specific columns with helper functions while using mutate.
In the following example, the sqrt function is applied to all columns containing "1" in their names. Subsequently, the new columns are named using the previous column name ("{.col}") followed by a suffix ("_sqrt").
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Create new columns with all columns that contain "1" in their names
df_2 <- df %>%
mutate(across(contains("1"), sqrt, .names = "{.col}_sqrt"))
df_2 Var1 Var2 Var1_sqrt
1 32 39 5.656854
2 34 1 5.830952
3 15 29 3.872983
4 12 3 3.464102
5 42 35 6.480741
Modify existing columns
The mutate function is also capable of modifying existing columns. To achieve this, simply use the syntax: old_column_name = expression
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Modify 'Var1' as its value divided by the mean of the column
df_2 <- df %>%
mutate(Var1 = Var1 / mean(Var1, na.rm = TRUE))
df_2 Var1 Var2
1 1.1851852 39
2 1.2592593 1
3 0.5555556 29
4 0.4444444 3
5 1.5555556 35Modify multiple columns
With across, you can select specific columns and apply a custom function to them without creating new columns. The example below demonstrates how to apply the log function to all columns except for Var1.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Apply log to all columns but 'Var1'
df_2 <- df %>%
mutate(across(!Var1, log))
df_2 Var1 Var2
1 32 3.663562
2 34 0.000000
3 15 3.367296
4 12 1.098612
5 42 3.555348
In such cases where the desired function takes additional arguments, you will need to use ~ before the function and reference . to represent the column values.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Modify all columns but 'Var1' with paste0
df_2 <- df %>%
mutate(across(!Var1, ~paste0("Value: ", .)))
df_2 Var1 Var2
1 32 Value: 39
2 34 Value: 1
3 15 Value: 29
4 12 Value: 3
5 42 Value: 35
Position of the new columns
By default, when you use mutate to create a new column, it appends that column to the end of the data frame. Nevertheless, the mutate function allows for the use of .before or .after arguments to control the position of the new columns relative to other columns.
In the example below, a new column is added before Var2:
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# New column before 'Var2'
df_2 <- df %>%
mutate(Var3 = Var1 / Var2, .before = Var2)
df_2 Var1 Var3 Var2
1 32 0.8205128 39
2 34 34.0000000 1
3 15 0.5172414 29
4 12 4.0000000 3
5 42 1.2000000 35
Additionally, you can specify positions based on the index of the column. For instance, setting .before = 1 will add the new column as the first column.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# New column on the first position (before first column)
df_2 <- df %>%
mutate(Var3 = Var1 / Var2, .before = 1)
df_2 Var3 Var1 Var2
1 0.8205128 32 39
2 34.0000000 34 1
3 0.5172414 15 29
4 4.0000000 12 3
5 1.2000000 42 35
In the example below, setting .after = "Var2" will place the new column after Var2.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# New column after 'Var2'
df_2 <- df %>%
mutate(Var3 = Var1 * Var2, .after = "Var2")
df_2 Var1 Var2 Var3
1 32 39 1248
2 34 1 34
3 15 29 435
4 12 3 36
5 42 35 1470
Keep or drop columns
When you add new columns to a data frame all other columns are preserved by default. However, the .keep argument, which defaults to "all", can also be set to "used" to only keep columns used inside mutate, to "unused" to keep unused columns and to "none" to delete all the old columns.
The following example demonstrates how to use .keep by retaining only used columns.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# New column and keep the new column ('Var3') and the column used ('Var1')
df_2 <- df %>%
mutate(Var3 = Var1 * 2, .keep = "used")
df_2 Var1 Var3
1 32 64
2 34 68
3 15 30
4 12 24
5 42 84
The opposite is to keep only the new column and the columns that haven’t been used setting .keep = "unused".
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# New column and keep the new column ('Var3') and the column unused ('Var2')
df_2 <- df %>%
mutate(Var3 = Var1 * 2, .keep = "unused")
df_2 Var2 Var3
1 39 64
2 1 68
3 29 30
4 3 24
5 35 84
Finally, to remove all columns from the original data frame, use .keep = "none".
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# New column and only keep the new column ('Var3')
df_2 <- df %>%
mutate(Var3 = Var1 * 2, .keep = "none")
df_2 Var3
1 64
2 68
3 30
4 24
5 84