Crear y modificar columnas en R con la función mutate() de dplyr
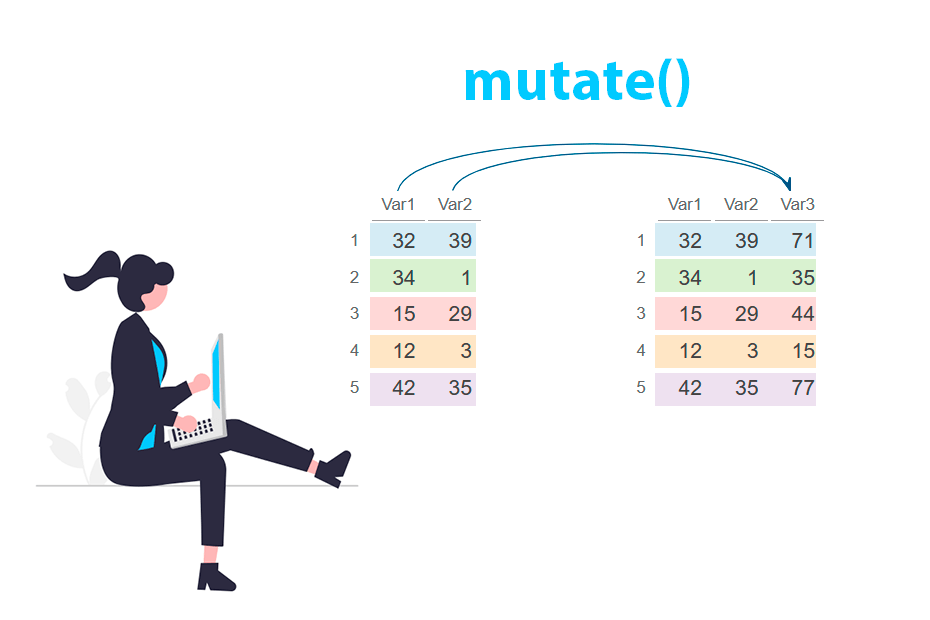
La función mutate del paquete dplyr se utiliza para crear nuevas columnas o modificar columnas existentes en un data frame, manteniendo la estructura original. Permite aplicar funciones u operaciones a los datos de un data frame y almacenar los resultados como nuevas variables.
Sintaxis
La sintaxis de la función mutate es la siguiente:
# Uso básico
mutate(.data, nuevo_nombre_columna = expresion)
mutate(
.data, # Conjunto de datos
..., # Nuevas columnas (nuevo_nombre_columna = expresion)
.by = NULL, # Agrupar por estas variables
.keep = c("all", "used", "unused", "none"), # Columnas que mantener
.before = NULL, # Las nuevas columnas aparecerán antes de esta
.after = NULL # Las nuevas columnas aparecerán después de esta
)Crear columnas
Para crear una nueva columna puedes especificar el nombre de la nueva columna (Var3) y una expresión para calcular los valores de la nueva columna. En el ejemplo siguiente, la expresión es la suma de otras dos columnas (Var1 + Var2).
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Nueva columna con la suma de 'Var1' y 'Var2'
df_2 <- df %>%
mutate(Var3 = Var1 + Var2)
df_2 Var1 Var2 Var3
1 32 39 71
2 34 1 35
3 15 29 44
4 12 3 15
5 42 35 77
También puedes aplicar una función a una columna para crear una nueva. El siguiente ejemplo ilustra cómo crear una nueva columna con la raíz cuadrada de otra.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Nueva columna con la raíz cuadrada de 'Var1'
df_2 <- df %>%
mutate(Sqrt_Var1 = sqrt(Var1))
df_2 Var1 Var2 Sqrt_Var1
1 32 39 5.656854
2 34 1 5.830952
3 15 29 3.872983
4 12 3 3.464102
5 42 35 6.480741
Agregar varias columnas nuevas a la vez
Ten en cuenta que puedes añadir varias columnas simultáneamente pasando más expresiones separadas por comas a mutate.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Crear tres nuevas columnas llamadas 'Var3', 'Var4' y 'Var5'
df_2 <- df %>%
mutate(Var3 = Var1 + Var2,
Var4 = cumsum(Var1),
Var5 = ifelse(Var1 > Var2, TRUE, FALSE))
df_2 Var1 Var2 Var3 Var4 Var5
1 32 39 71 32 FALSE
2 34 1 35 66 TRUE
3 15 29 44 81 FALSE
4 12 3 15 93 TRUE
5 42 35 77 135 TRUE
Usando across
La función across permite seleccionar columnas específicas con funciones de selección mientras se utiliza mutate.
En el siguiente ejemplo, la función sqrt se aplica a todas las columnas que contienen "1" en sus nombres. A continuación, las nuevas columnas reciben el nombre de la columna anterior ("{.col}") seguido de un sufijo ("_sqrt").
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Crear nuevas columnas con todas las columnas que contienen "1" en sus nombres
df_2 <- df %>%
mutate(across(contains("1"), sqrt, .names = "{.col}_sqrt"))
df_2 Var1 Var2 Var1_sqrt
1 32 39 5.656854
2 34 1 5.830952
3 15 29 3.872983
4 12 3 3.464102
5 42 35 6.480741
Modificar columnas existentes
La función mutate también es capaz de modificar columnas existentes. Para ello, basta con utilizar la sintaxis nombre_columna_antigua = expresion
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Modifica 'Var1' como su valor dividido por la media de la columna
df_2 <- df %>%
mutate(Var1 = Var1 / mean(Var1, na.rm = TRUE))
df_2 Var1 Var2
1 1.1851852 39
2 1.2592593 1
3 0.5555556 29
4 0.4444444 3
5 1.5555556 35Modificar varias columnas
Con across puedes seleccionar columnas específicas y aplicarles una función personalizada sin crear nuevas columnas. El siguiente ejemplo muestra cómo aplicar la función log a todas las columnas excepto a Var1.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Aplicar la función log a todas las columnas menos a 'Var1'
df_2 <- df %>%
mutate(across(!Var1, log))
df_2 Var1 Var2
1 32 3.663562
2 34 0.000000
3 15 3.367296
4 12 1.098612
5 42 3.555348
En los casos en los que la función deseada tome argumentos adicionales, deberás utilizar ~ antes de la función y . para representar los valores de las columnas.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Modificar todas las columnas menos 'Var1' con paste0
df_2 <- df %>%
mutate(across(!Var1, ~paste0("Value: ", .)))
df_2 Var1 Var2
1 32 Value: 39
2 34 Value: 1
3 15 Value: 29
4 12 Value: 3
5 42 Value: 35
Posición de las nuevas columnas
Por defecto, cuando se utiliza mutate para crear una nueva columna, ésta se añade al final del data frame. No obstante, la función mutate permite utilizar los argumentos .before o .after para controlar la posición de las nuevas columnas respecto a otras.
En el ejemplo siguiente, se añade una nueva columna antes de Var2:
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# New column before 'Var2'
df_2 <- df %>%
mutate(Var3 = Var1 / Var2, .before = Var2)
df_2 Var1 Var3 Var2
1 32 0.8205128 39
2 34 34.0000000 1
3 15 0.5172414 29
4 12 4.0000000 3
5 42 1.2000000 35
Además, puedes especificar posiciones basadas en el índice de la columna. Por ejemplo, establecer .before = 1 añadirá la nueva columna como la primera columna.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Nueva columna en la primera posición (antes de la primera columna)
df_2 <- df %>%
mutate(Var3 = Var1 / Var2, .before = 1)
df_2 Var3 Var1 Var2
1 0.8205128 32 39
2 34.0000000 34 1
3 0.5172414 15 29
4 4.0000000 12 3
5 1.2000000 42 35
En el ejemplo siguiente, si se establece .after = "Var2", la nueva columna se situará después de Var2.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Nueva columna después de 'Var2'
df_2 <- df %>%
mutate(Var3 = Var1 * Var2, .after = "Var2")
df_2 Var1 Var2 Var3
1 32 39 1248
2 34 1 34
3 15 29 435
4 12 3 36
5 42 35 1470
Mantener o eliminar columnas con keep
Cuando se añaden nuevas columnas a un data frame, todas las demás columnas se mantendrán por defecto. Sin embargo, el argumento .keep, que por defecto es "all", también puede establecerse a "used" para conservar sólo las columnas utilizadas dentro de mutate, a "unused" para conservar las columnas no utilizadas y a "none" para borrar todas las columnas antiguas.
El siguiente ejemplo muestra cómo utilizar .keep manteniendo sólo las columnas utilizadas.
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Nueva columna y mantener la nueva columna ('Var3') y la columna utilizada ('Var1')
df_2 <- df %>%
mutate(Var3 = Var1 * 2, .keep = "used")
df_2 Var1 Var3
1 32 64
2 34 68
3 15 30
4 12 24
5 42 84
Lo contrario es mantener sólo la nueva columna y las columnas que no se han utilizado estableciendo .keep = "unused".
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Nueva columna y mantener la nueva columna ('Var3') y la columna no utilizada ('Var2')
df_2 <- df %>%
mutate(Var3 = Var1 * 2, .keep = "unused")
df_2 Var2 Var3
1 39 64
2 1 68
3 29 30
4 3 24
5 35 84
Por último, para eliminar todas las columnas del data frame original, utiliza .keep = "none".
library(dplyr)
set.seed(8)
df <- data.frame(Var1 = sample(1:50, 5), Var2 = sample(1:50, 5))
# Nueva columna y sólo mantener la nueva columna ('Var3')
df_2 <- df %>%
mutate(Var3 = Var1 * 2, .keep = "none")
df_2 Var3
1 64
2 68
3 30
4 24
5 84