Web scraping in R with rvest

Web scraping is a technique used for automatically extracting data from web pages. In this tutorial, we will demonstrate how to scrape data from static websites using the rvest library. Basic knowledge of HTML and CSS is required to follow along with this tutorial.
Web scraping is considered a legal technique in most cases, but we encourage you to learn more about web scraping before scraping any website and to check their robots.txt file and their terms of use.
The sample site
In this tutorial we are going to scrape a website designed to practice web scraping skills named http://books.toscrape.com/. If you enter to this website you will see the following:
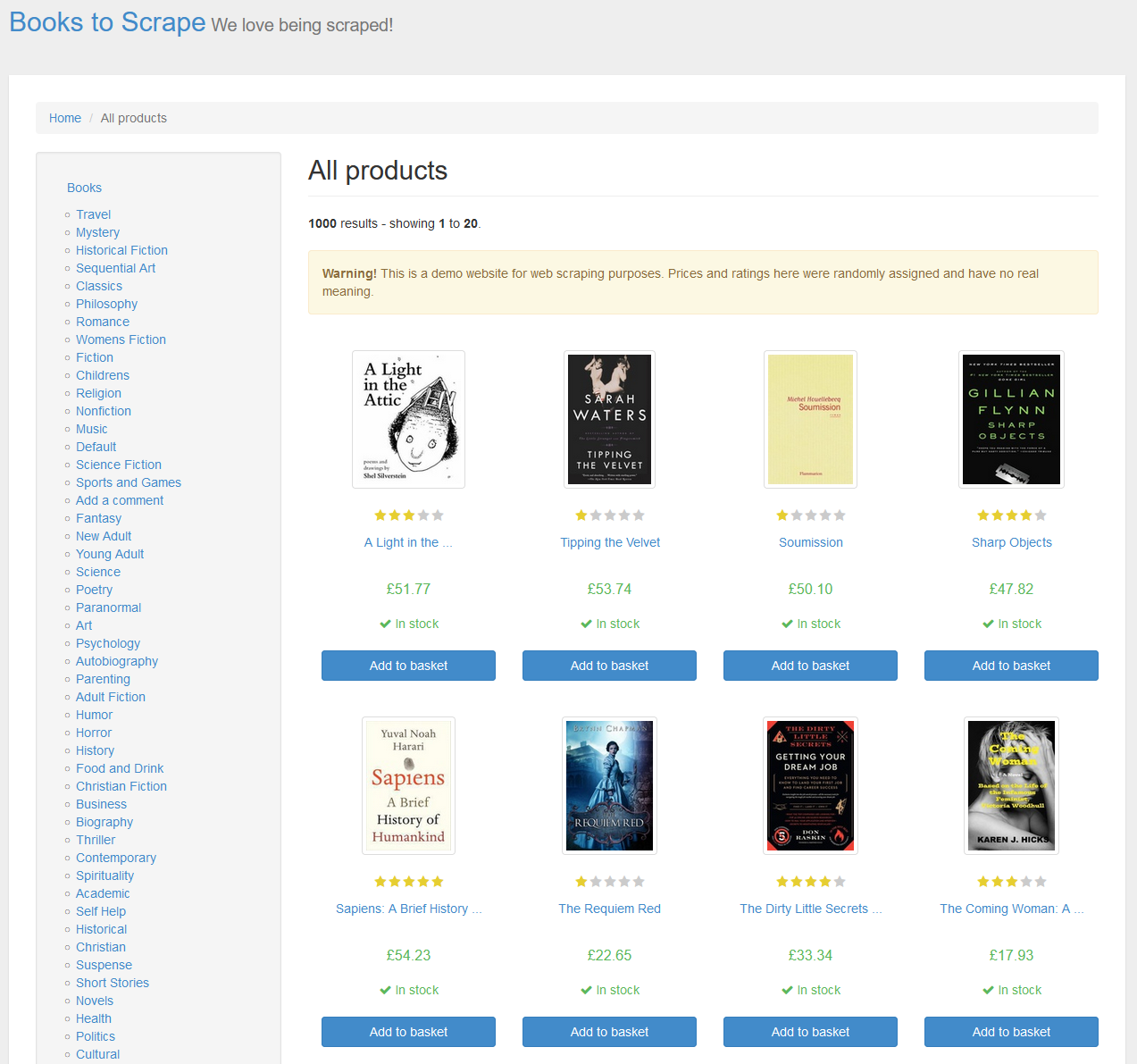
Read the HTML of the site
The first step to retrieve data from a web page is to download its HTML. Given a URL you can download its HTML with the read_html function from rvest.
# install.packages("rvest")
library(rvest)
# URL to scrape
url <- "http://books.toscrape.com/"
# Download the HTML code of the page
html <- url %>%
read_html()
# View HTML
html{html_document}
<html lang="en-us" class="no-js">
[1] <head>\n<title>\n All products | Books to Scrape - Sandbox\n</title>\n<meta http-equiv="content-type" content="text/html; charset=UTF-8">\n<meta name="created" content="24th Jun 2016 09:29">\n<meta name="description" ...
[2] <body id="default" class="default">\n \n \n \n \n <header class="header container-fluid"><div class="page_inner">\n <div class="row">\n <div class="col-sm-8 h1">\n<a href ...Elements
Once you have downloaded the HTML of the page you will be able to obtain the desired data. To do this you will have to select the desired elements or nodes with the html_element or html_elements functions to scrape the first or all occurrences.
html_element and html_elements are also named html_node and html_nodes.
CSS selectors
For instance, if you want to get the heading of the page (the h1 tag) you can specify it inside the html_element function and then return the inner text with html_text2.
html %>%
html_element("h1") %>%
html_text2()"All products"Now consider that you want to get all the titles of the books. If you inspect the website, you will see that the titles are inside H3 tags:
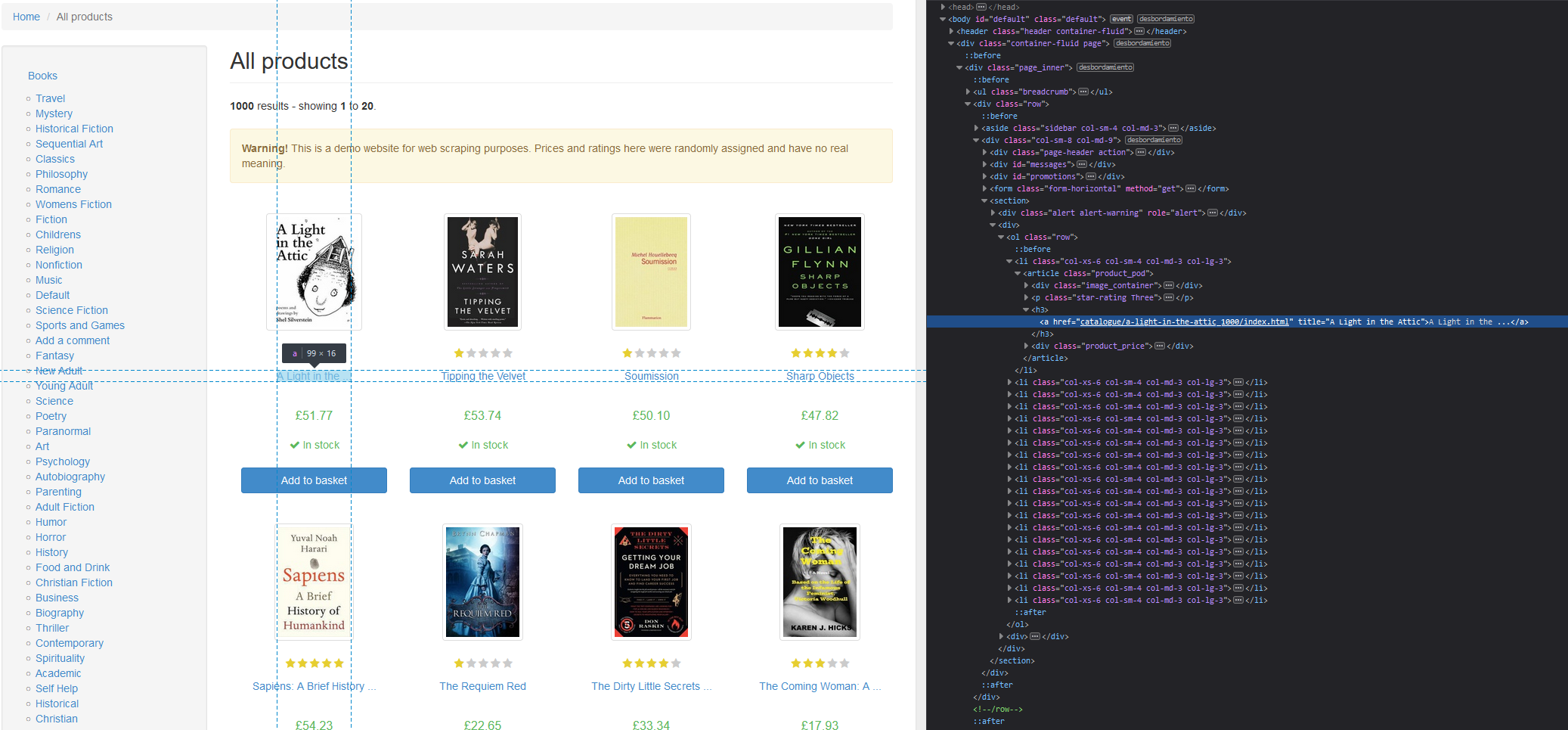
Once you know which element to scrape specify it inside html_elements and get the inner text with html_text2.
book_titles <- html %>%
html_elements("h3") %>%
html_text2()
book_titles [1] "A Light in the ..." "Tipping the Velvet" "Soumission" "Sharp Objects" "Sapiens: A Brief History ..."
[6] "The Requiem Red" "The Dirty Little Secrets ..." "The Coming Woman: A ..." "The Boys in the ..." "The Black Maria"
[11] "Starving Hearts (Triangular Trade ..." "Shakespeare's Sonnets" "Set Me Free" "Scott Pilgrim's Precious Little ..." "Rip it Up and ..."
[16] "Our Band Could Be ..." "Olio" "Mesaerion: The Best Science ..." "Libertarianism for Beginners" "It's Only the Himalayas" The html_elements function also works with CSS classes and ids. Inspecting the site you will see that all prices have a class called price_color, so to download them you can input ".price_color" to html_elements.
book_prices <- html %>%
html_elements(".price_color") %>%
html_text2()
book_prices"£51.77" "£53.74" "£50.10" "£47.82" "£54.23" "£22.65" "£33.34" "£17.93" "£22.60" "£52.15" "£13.99" "£20.66" "£17.46" "£52.29" "£35.02" "£57.25" "£23.88" "£37.59" "£51.33" "£45.17"Add . before CSS classes names and # before IDs to select them.
Xpath
XPath is a language that allows to select elements based on a route. In order to copy the XPath of an element using the developer tools of your browser select the desired element inside the tools and then do: Right click→Copy→XPath. Then, you can input the XPath to the xpath argument of the html_elements or html_element function:
title <- html %>%
html_elements(xpath = "/html/body/div/div/div/div/div[1]/h1")
title{xml_nodeset (1)}
[1] <h1>All products</h1>Children
The rvest package provides a function to get the children elements named html_children. For instance, the children of the H3 headings are their links.
book_links <- html %>%
html_elements("h3") %>%
html_children()
head(book_links){xml_nodeset (6)}
[1] <a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a>
[2] <a href="catalogue/tipping-the-velvet_999/index.html" title="Tipping the Velvet">Tipping the Velvet</a>
[3] <a href="catalogue/soumission_998/index.html" title="Soumission">Soumission</a>
[4] <a href="catalogue/sharp-objects_997/index.html" title="Sharp Objects">Sharp Objects</a>
[5] <a href="catalogue/sapiens-a-brief-history-of-humankind_996/index.html" title="Sapiens: A Brief History of Humankind">Sapiens: A Brief History ...</a>
[6] <a href="catalogue/the-requiem-red_995/index.html" title="The Requiem Red">The Requiem Red</a>Attributes
rvest provide two functions named html_attr and html_attrs which returns a single attribute (the one specified) or all attributes of a node, respectively.
In the previous examples we got the titles of the books, but the titles were truncated. Inspecting the HTML of the site you can see that each H3 has a link with an attribute named title that contains the full name of each book, so to get them you can do the following:
book_titles <- html %>%
html_elements("h3") %>%
html_elements("a") %>%
html_attr("title")
book_titles [1] "A Light in the Attic" "Tipping the Velvet"
[3] "Soumission" "Sharp Objects"
[5] "Sapiens: A Brief History of Humankind" "The Requiem Red"
[7] "The Dirty Little Secrets of Getting Your Dream Job" "The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull"
[9] "The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics" "The Black Maria"
[11] "Starving Hearts (Triangular Trade Trilogy, #1)" "Shakespeare's Sonnets"
[13] "Set Me Free" "Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)"
[15] "Rip it Up and Start Again" "Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991"
[17] "Olio" "Mesaerion: The Best Science Fiction Stories 1800-1849"
[19] "Libertarianism for Beginners" "It's Only the Himalayas" With the html_attrs function you can extract all the attributes of a node. The example below extracts all the attributes within the link of the H3 headings and merges them into a matrix.
link_attrs <- html %>%
html_elements("h3") %>%
html_elements("a") %>%
html_attrs()
# Merge the list into a matrix
link_attrs <- do.call(rbind, link_attrs)
head(link_attrs) href title
[1,] "catalogue/a-light-in-the-attic_1000/index.html" "A Light in the Attic"
[2,] "catalogue/tipping-the-velvet_999/index.html" "Tipping the Velvet"
[3,] "catalogue/soumission_998/index.html" "Soumission"
[4,] "catalogue/sharp-objects_997/index.html" "Sharp Objects"
[5,] "catalogue/sapiens-a-brief-history-of-humankind_996/index.html" "Sapiens: A Brief History of Humankind"
[6,] "catalogue/the-requiem-red_995/index.html" "The Requiem Red" You could paste the URL with the links and scrape them if you want to continue scraping the details for each book.
Tables
The html_table function allows to scrape tables in a simple way, since it is only necessary to input the HTML document and it will download all the tables available in the page.
In the example below we are extracting the URL of the first book of the page and its HTML.
# Get links
links <- html %>%
html_elements("h3") %>%
html_elements("a") %>%
html_attr("href")
links <- paste0("http://books.toscrape.com/", links)
# Get link of the first book
book_link <- links[1] # http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
# Read HTML of the book page
html_book <- book_link %>%
read_html()The page is the following:
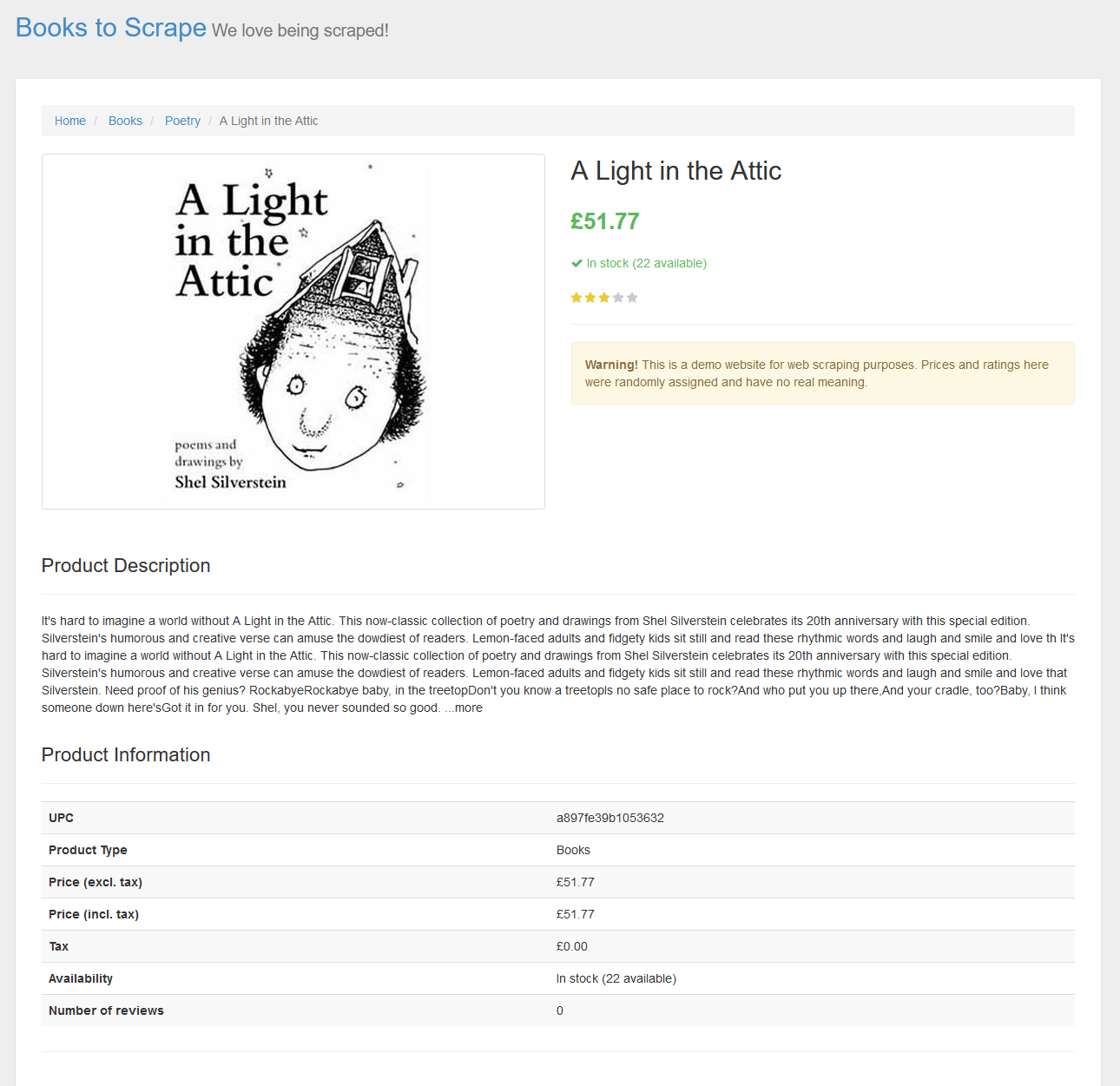
The scraped page has a table with information about the book. Using the html_table function you can download the table, as shown below.
book_table <- html_book %>%
html_table()
# View the table
book_table[[1]]
# A tibble: 7 × 2
X1 X2
<chr> <chr>
1 UPC a897fe39b1053632
2 Product Type Books
3 Price (excl. tax) £51.77
4 Price (incl. tax) £51.77
5 Tax £0.00
6 Availability In stock (22 available)
7 Number of reviews 0 




