Web scraping en R con rvest

Web scraping es una técnica para extraer automáticamente datos de páginas web. En este tutorial revisaremos cómo scrapear datos de páginas web estáticas utilizando la librería rvest. Necesitarás conocimientos básicos de HTML y CSS para seguir este tutorial.
El web scraping se considera una técnica legal en la mayoría de los casos, pero te animamos a aprender más sobre el web scraping antes de hacer scraping de cualquier sitio web y a que compruebes su archivo robots.txt y sus condiciones de uso.
Página web
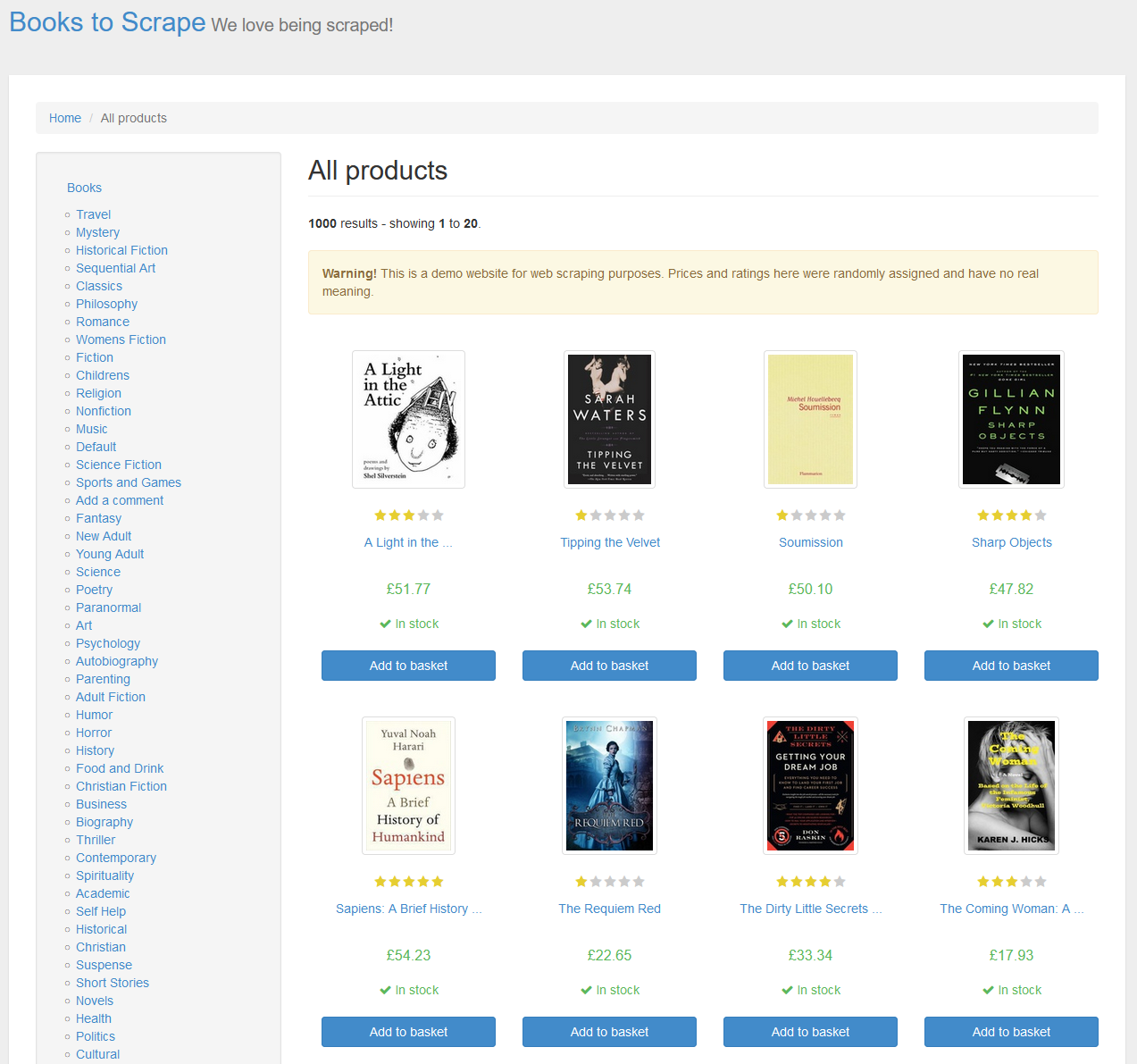
En este tutorial vamos a scrapear un sitio web diseñado para practicar habilidades de web scraping llamado http://books.toscrape.com/. Si entras en este sitio web verás lo siguiente:
Leer el HTML del sitio con read_html
El primer paso para obtener datos de una página web es descargar su HTML. Dada una URL puedes descargar su HTML con la función read_html de rvest.
# install.packages("rvest")
library(rvest)
# URL para scrapear
url <- "http://books.toscrape.com/"
# Descargar el HTML de una página
html <- url %>%
read_html()
# Ver el HTML
html{html_document}
<html lang="en-us" class="no-js">
[1] <head>\n<title>\n All products | Books to Scrape - Sandbox\n</title>\n<meta http-equiv="content-type" content="text/html; charset=UTF-8">\n<meta name="created" content="24th Jun 2016 09:29">\n<meta name="description" ...
[2] <body id="default" class="default">\n \n \n \n \n <header class="header container-fluid"><div class="page_inner">\n <div class="row">\n <div class="col-sm-8 h1">\n<a href ...Elementos
Una vez descargado el HTML de la página podrás obtener los datos deseados. Para ello tendrás que seleccionar los elementos o nodos deseados con las funciones html_element o html_elements para scrapear la primera o todas las ocurrencias.
html_element y html_elements también se llaman html_node y html_nodes.
Selectores CSS
Por ejemplo, si quieres obtener el encabezado de la página (la etiqueta h1) puedes especificarlo dentro de la función html_element y luego devolver el texto interior con html_text2.
html %>%
html_element("h1") %>%
html_text2()"All products"Ahora considera que quieres obtener todos los títulos de los libros. Si inspeccionas el sitio web, verás que los títulos están dentro de etiquetas H3:
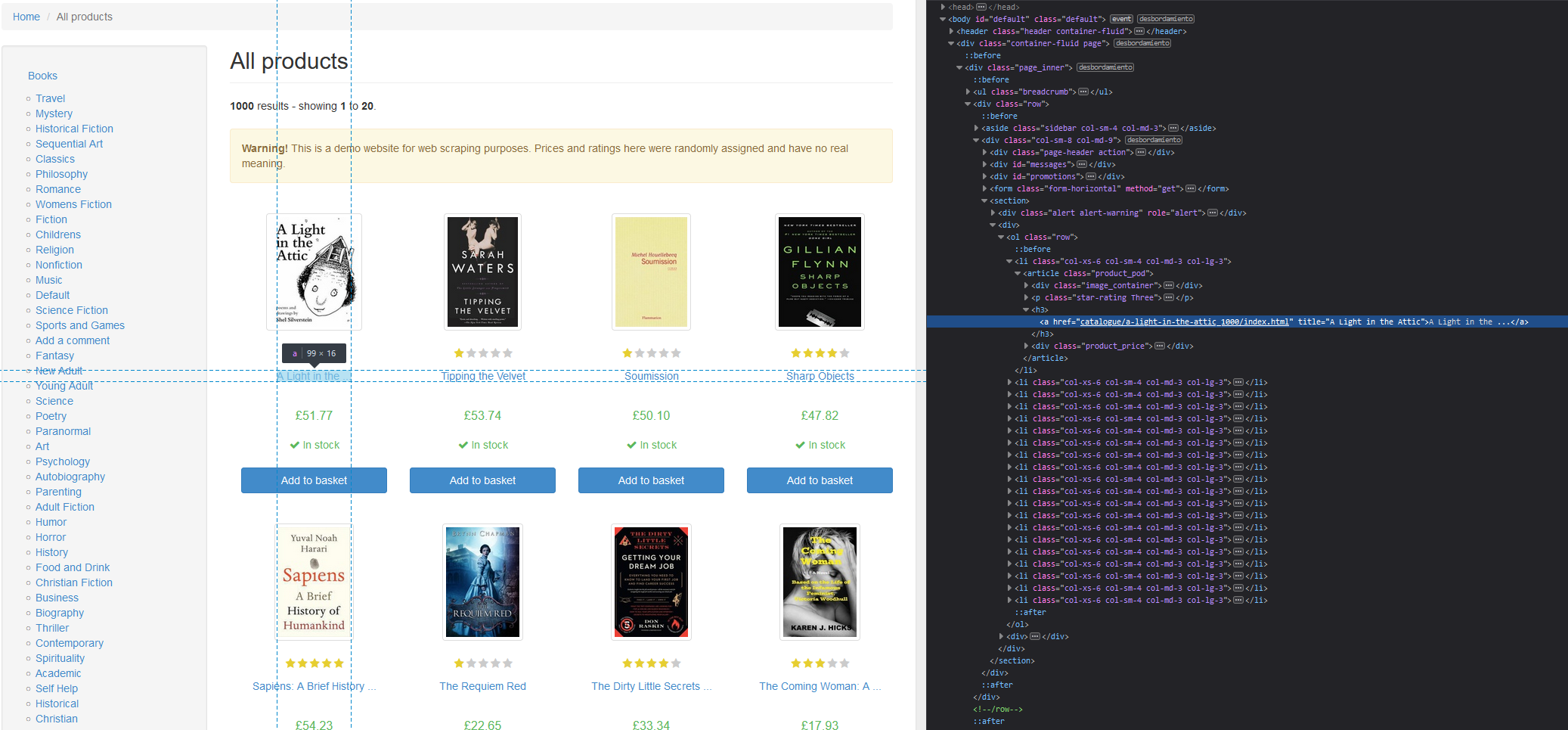
Una vez que sepas qué elemento scrapear especifícalo dentro de html_elements y obtén el texto interior con html_text2.
titulos_libros <- html %>%
html_elements("h3") %>%
html_text2()
titulos_libros [1] "A Light in the ..." "Tipping the Velvet" "Soumission" "Sharp Objects" "Sapiens: A Brief History ..."
[6] "The Requiem Red" "The Dirty Little Secrets ..." "The Coming Woman: A ..." "The Boys in the ..." "The Black Maria"
[11] "Starving Hearts (Triangular Trade ..." "Shakespeare's Sonnets" "Set Me Free" "Scott Pilgrim's Precious Little ..." "Rip it Up and ..."
[16] "Our Band Could Be ..." "Olio" "Mesaerion: The Best Science ..." "Libertarianism for Beginners" "It's Only the Himalayas" La función html_elements también funciona con clases CSS e ids. Inspeccionando el sitio verás que todos los precios tienen una clase llamada price_color, así que para descargarlos puedes introducir ".price_color" en html_elements.
precios_libros <- html %>%
html_elements(".price_color") %>%
html_text2()
precios_libros"£51.77" "£53.74" "£50.10" "£47.82" "£54.23" "£22.65" "£33.34" "£17.93" "£22.60" "£52.15" "£13.99" "£20.66" "£17.46" "£52.29" "£35.02" "£57.25" "£23.88" "£37.59" "£51.33" "£45.17"Añade . antes de los nombres de las clases CSS y # antes de los IDs para seleccionarlos.
Xpath
XPath es un lenguaje que permite seleccionar elementos en base a una ruta. Para copiar el XPath de un elemento usando las herramientas de desarrollo de tu navegador selecciona el elemento que quieras dentro de las herramientas y haz: Clic derecho→Copiar→XPath. A continuación, puedes introducir el XPath en el argumento xpath de la función html_elements o html_element:
titulo <- html %>%
html_elements(xpath = "/html/body/div/div/div/div/div[1]/h1")
titulo{xml_nodeset (1)}
[1] <h1>All products</h1>
Elementos hijo con html_children
El paquete rvest proporciona una función para obtener los elementos hijos llamada html_children. Por ejemplo, los hijos de los encabezados H3 son sus enlaces.
links_libros <- html %>%
html_elements("h3") %>%
html_children()
head(links_libros){xml_nodeset (6)}
[1] <a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a>
[2] <a href="catalogue/tipping-the-velvet_999/index.html" title="Tipping the Velvet">Tipping the Velvet</a>
[3] <a href="catalogue/soumission_998/index.html" title="Soumission">Soumission</a>
[4] <a href="catalogue/sharp-objects_997/index.html" title="Sharp Objects">Sharp Objects</a>
[5] <a href="catalogue/sapiens-a-brief-history-of-humankind_996/index.html" title="Sapiens: A Brief History of Humankind">Sapiens: A Brief History ...</a>
[6] <a href="catalogue/the-requiem-red_995/index.html" title="The Requiem Red">The Requiem Red</a>Atributos
rvest proporciona dos funciones llamadas html_attr y html_attrs que devuelven un único atributo (el especificado) o todos los atributos de un nodo, respectivamente.
En los ejemplos anteriores obtuvimos los títulos de los libros, pero los títulos estaban truncados. Inspeccionando el HTML del sitio puedes ver que cada H3 tiene un enlace con un atributo llamado title que contiene el nombre completo de cada libro, así que para obtenerlos puedes hacer lo siguiente:
titulos_libros <- html %>%
html_elements("h3") %>%
html_elements("a") %>%
html_attr("title")
titulos_libros [1] "A Light in the Attic" "Tipping the Velvet"
[3] "Soumission" "Sharp Objects"
[5] "Sapiens: A Brief History of Humankind" "The Requiem Red"
[7] "The Dirty Little Secrets of Getting Your Dream Job" "The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull"
[9] "The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics" "The Black Maria"
[11] "Starving Hearts (Triangular Trade Trilogy, #1)" "Shakespeare's Sonnets"
[13] "Set Me Free" "Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)"
[15] "Rip it Up and Start Again" "Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991"
[17] "Olio" "Mesaerion: The Best Science Fiction Stories 1800-1849"
[19] "Libertarianism for Beginners" "It's Only the Himalayas" Con la función html_attrs puedes extraer todos los atributos de un elemento. El siguiente ejemplo extrae todos los atributos dentro del enlace de los encabezados H3 y los une en una matriz.
atributos_links <- html %>%
html_elements("h3") %>%
html_elements("a") %>%
html_attrs()
# Unimos la lista en una matriz
atributos_links <- do.call(rbind, atributos_links)
head(atributos_links) href title
[1,] "catalogue/a-light-in-the-attic_1000/index.html" "A Light in the Attic"
[2,] "catalogue/tipping-the-velvet_999/index.html" "Tipping the Velvet"
[3,] "catalogue/soumission_998/index.html" "Soumission"
[4,] "catalogue/sharp-objects_997/index.html" "Sharp Objects"
[5,] "catalogue/sapiens-a-brief-history-of-humankind_996/index.html" "Sapiens: A Brief History of Humankind"
[6,] "catalogue/the-requiem-red_995/index.html" "The Requiem Red" Podrías pegar la URL con los enlaces y leer su HTML si quieres seguir scrapeando los detalles de cada libro.
Descargar tablas con html_table
La función html_table permite scrapear tablas de manera sencilla, ya que sólo es necesario introducir el documento HTML y descargará todas las tablas disponibles en la página.
En el siguiente ejemplo estamos extrayendo la URL del primer libro de la página y su HTML.
# Obtener enlaces
links <- html %>%
html_elements("h3") %>%
html_elements("a") %>%
html_attr("href")
links <- paste0("http://books.toscrape.com/", links)
# Link del primer libro
link_libro <- links[1] # http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
# HTML de la página del libro
html_libro <- link_libro %>%
read_html()La página es la siguiente:
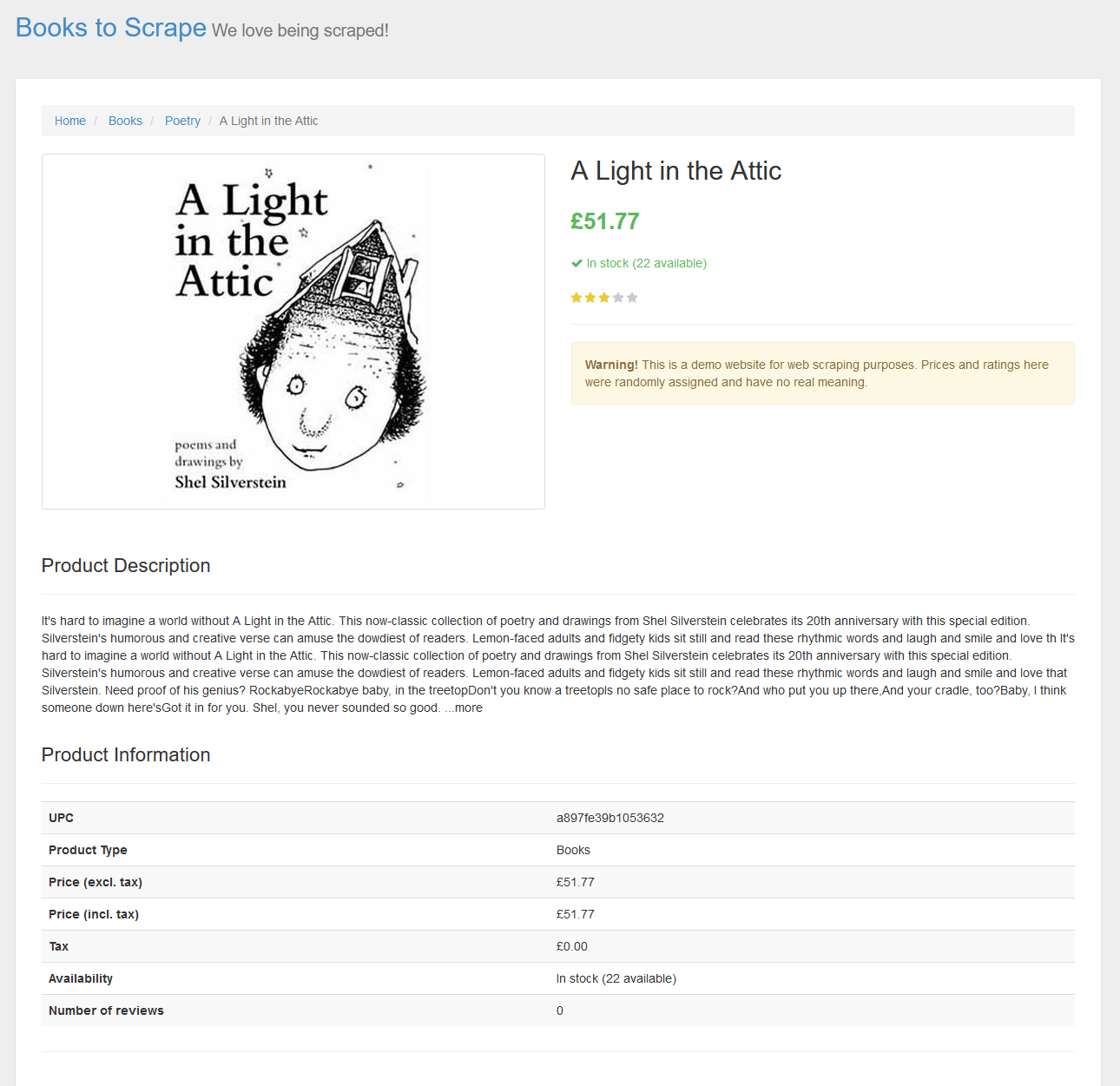
La página scrapeada contiene una tabla con información sobre el libro. Usando la función html_table puedes descargar la tabla, como se muestra a continuación.
tabla_libro <- html_libro %>%
html_table()
# Vemos la tabla
tabla_libro[[1]]
# A tibble: 7 × 2
X1 X2
<chr> <chr>
1 UPC a897fe39b1053632
2 Product Type Books
3 Price (excl. tax) £51.77
4 Price (incl. tax) £51.77
5 Tax £0.00
6 Availability In stock (22 available)
7 Number of reviews 0 




