Select columns in R with dplyr
Select or remove columns from a data frame with the select function from dplyr and learn how to use helper functions to select columns such as contains, matches, all_of, any_of, starts_with, ends_with, last_col, where, num_range and everything.
Sample data
In this tutorial we will use as example data the first five rows and the first six columns of the starwars data set from dplyr.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# View data
df# A tibble: 5 × 6
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Luke Skywalker 172 77 blond fair blue
2 C-3PO 167 75 NA gold yellow
3 R2-D2 96 32 NA white, blue red
4 Darth Vader 202 136 none white yellow
5 Leia Organa 150 49 brown light brown Select columns
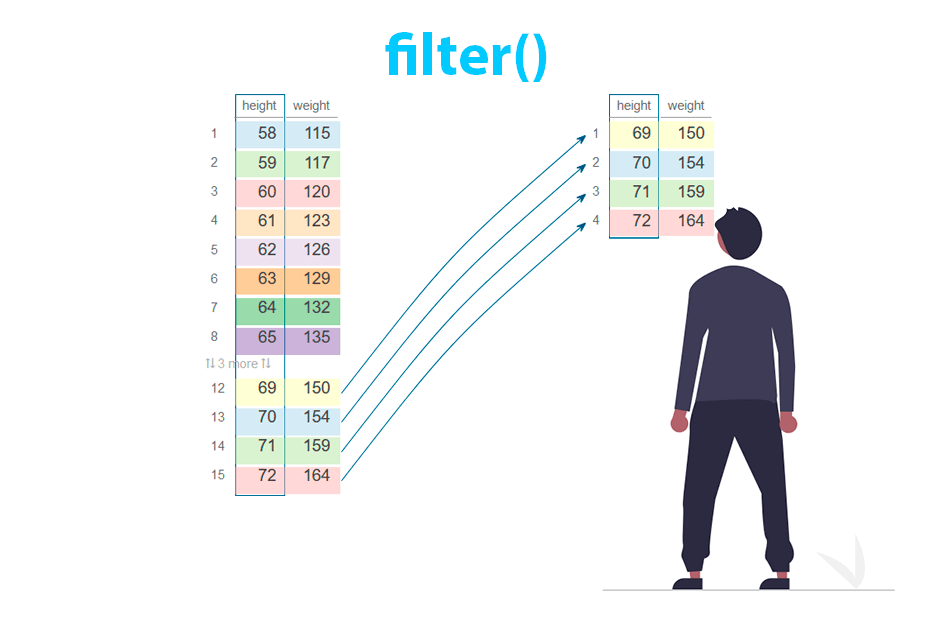
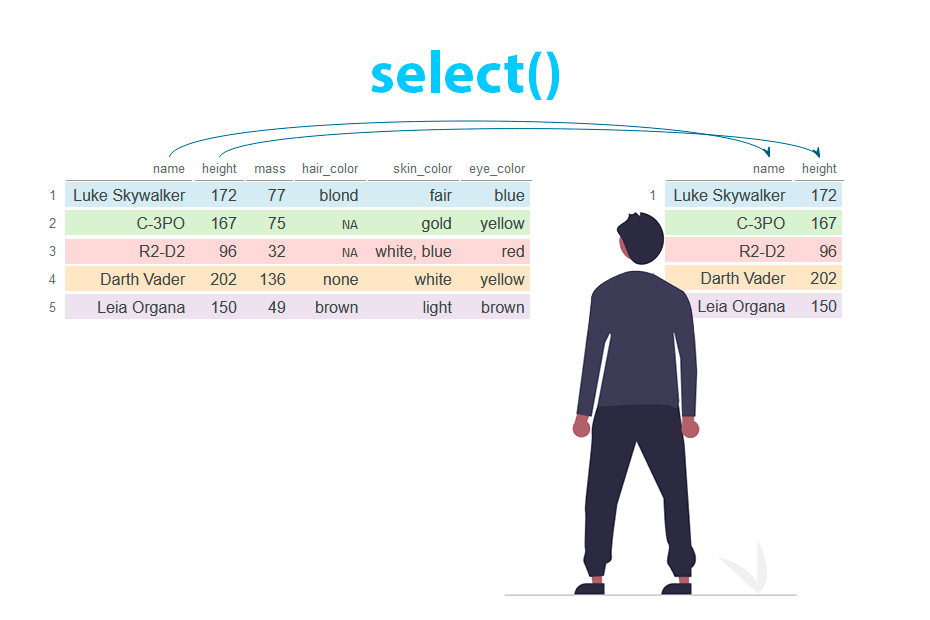
The select function allows to filter columns from a data frame. Columns can be selected either by name or index/position.
By name
Given a dataset you will need to specify the desired columns inside select with or without quotes. Note that you can select one or multiple columns.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Select columns named 'name' and 'height'
df_2 <- df %>%
select(name, height) # Or select(c("name", "height"))
df_2# A tibble: 6 × 2
name height
<chr> <int>
1 Luke Skywalker 172
2 C-3PO 167
3 R2-D2 96
4 Darth Vader 202
5 Leia Organa 150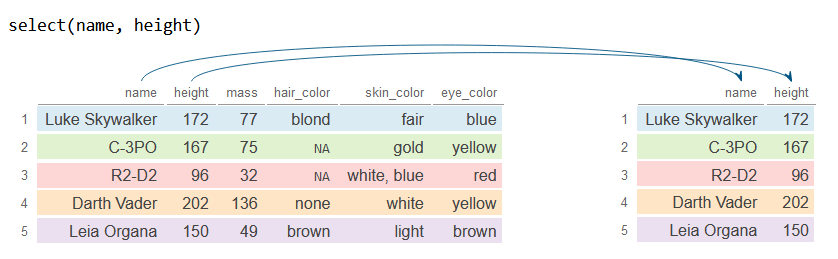
You can also select a sequence of columns using :. For instance, if you want to select the columns from height to skin_color, both included, you can type: height:skin_color
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Select columns from 'height' to 'skin_color'
df_2 <- df %>%
select(height:skin_color)
df_2# A tibble: 5 × 4
height mass hair_color skin_color
<int> <dbl> <chr> <chr>
1 172 77 blond fair
2 167 75 NA gold
3 96 32 NA white, blue
4 202 136 none white
5 150 49 brown light 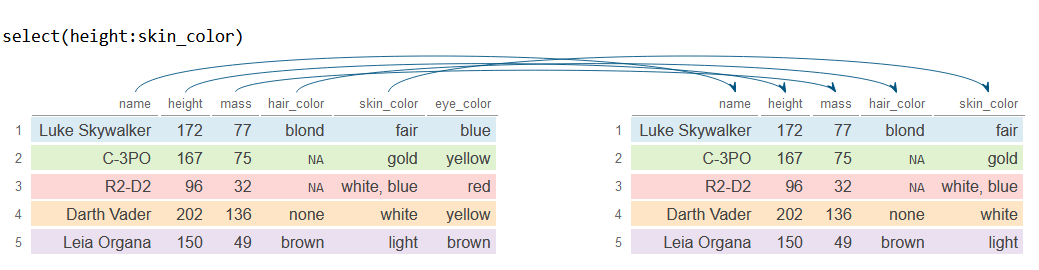
By index
Columns can also be selected by index. To do so you just have to specify the desired column numbers inside select. The following example selects the first, the fifth and the sixth column.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Select first, fifth and sixth column
df_2 <- df %>%
select(1, 5, 6)
df_2# A tibble: 5 × 3
name skin_color eye_color
<chr> <chr> <chr>
1 Luke Skywalker fair blue
2 C-3PO gold yellow
3 R2-D2 white, blue red
4 Darth Vader white yellow
5 Leia Organa light brown 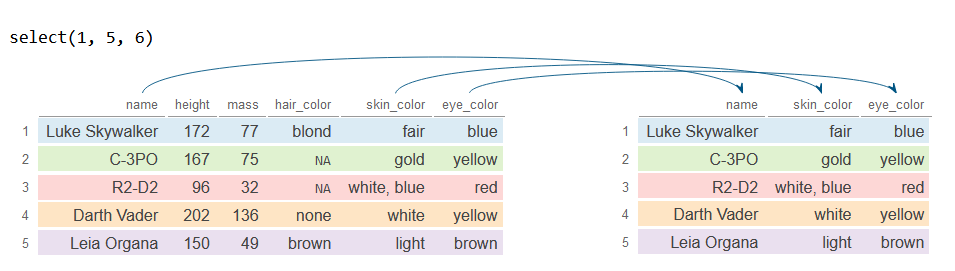
In addition, you can create a sequence of numbers to select a range of columns. The example below can be used to select the first n columns.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# First 4 columns
n <- 4
# Select first four columns
df_2 <- df %>%
select(1:n)
df_2# A tibble: 5 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Luke Skywalker 172 77 blond
2 C-3PO 167 75 NA
3 R2-D2 96 32 NA
4 Darth Vader 202 136 none
5 Leia Organa 150 49 brown 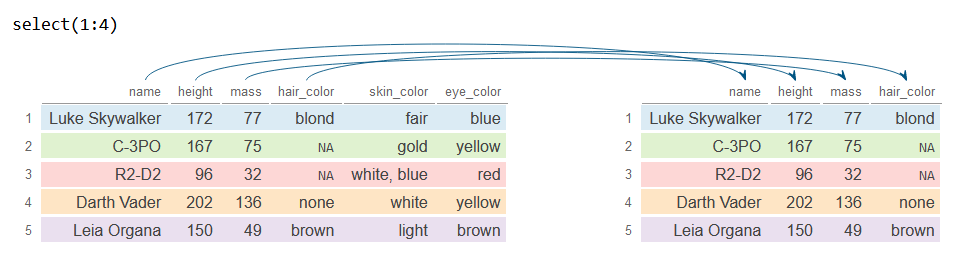
Drop columns
The select function can also be used to filter out certain columns. To do this, it is only necessary to add the symbol - before each column name. In the following example we select all columns except mass.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Select all columns but 'mass'
df_2 <- df %>%
select(-mass)
df_2# A tibble: 5 × 5
name height hair_color skin_color eye_color
<chr> <int> <chr> <chr> <chr>
1 Luke Skywalker 172 blond fair blue
2 C-3PO 167 NA gold yellow
3 R2-D2 96 NA white, blue red
4 Darth Vader 202 none white yellow
5 Leia Organa 150 brown light brown 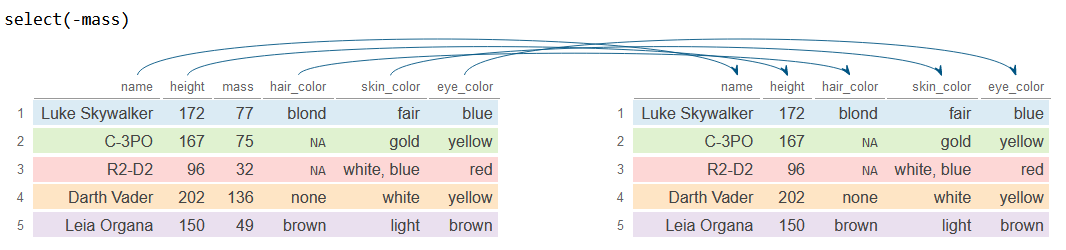
In case you want to drop several columns you can add - before each column name or before a vector with the names.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Drop 'height', 'mass' and 'hair_color'
df_2 <- df %>%
select(-height, -mass, -hair_color) # Or -c(height, mass, hair_color)
df_2# A tibble: 5 × 3
name skin_color eye_color
<chr> <chr> <chr>
1 Luke Skywalker fair blue
2 C-3PO gold yellow
3 R2-D2 white, blue red
4 Darth Vader white yellow
5 Leia Organa light brown 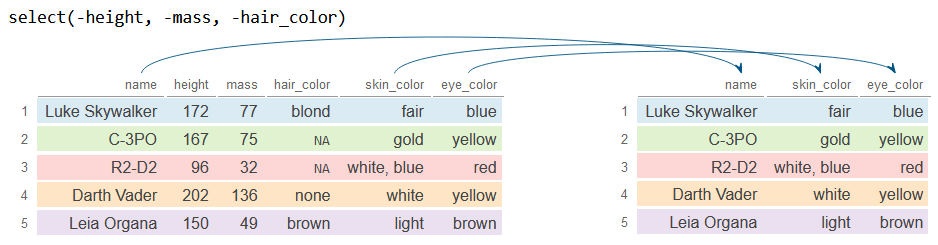
To remove a range of columns you will have to use the - operator and add the sequence of columns inside parenthesis, as in the example below.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Select all columns except the fourth, the fifth and the sixth
df_2 <- df %>%
select(-(4:6))
df_2# A tibble: 5 × 3
name height mass
<chr> <int> <dbl>
1 Luke Skywalker 172 77
2 C-3PO 167 75
3 R2-D2 96 32
4 Darth Vader 202 136
5 Leia Organa 150 49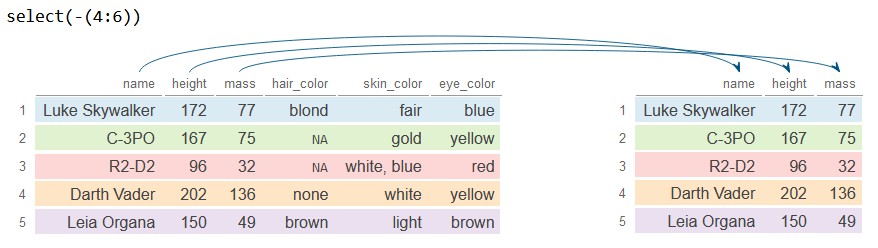
Exclamation operator
Note that in addition to the minus operator (-) there is the exclamation operator (!), which negates the selection criteria. This means that selects all columns and excludes those matching the selection criteria.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Select ALL EXCEPT "name"
df_2 <- df %>%
select(!name)
df_2# A tibble: 5 × 5
height mass hair_color skin_color eye_color
<int> <dbl> <chr> <chr> <chr>
1 172 77 blond fair blue
2 167 75 NA gold yellow
3 96 32 NA white, blue red
4 202 136 none white yellow
5 150 49 brown light brown Don’t confuse the minus symbol (-) with the exclamation mark (!). While both operators are used for excluding columns in dplyr’s select function, the - operator explicitly specifies columns to remove, whereas the ! operator selects ALL columns EXCEPT those that match the criteria specified.
Helper functions to select or remove columns
There are several helper functions to select columns based on patterns, such as contains, starts_with, ends_with, matches and num_range, based on a condition with where, based on character vectors such as any_of and all_of etc. The following table describes the most common functions and their usage.
| Function | Description |
|---|---|
contains("text") |
Selects columns containing the given text (exact match) |
all_of(c("col1", "col2")) |
Selects all columns based on a character vector |
any_of(c("col1", "col2")) |
Selects columns based on a character vector, even if some do not exist |
starts_with("prefix") |
Selects columns starting with the given prefix (exact match) |
ends_with("suffix") |
Selects columns ending with the given suffix (exact match) |
last_col() |
Select the last column |
matches("regex") |
Selects columns that match a regular expression |
num_range("prefix", 1:5) |
Selects columns with a prefix and numeric range in their names |
where() |
Selects columns that meet a given condition, e.g. where(is.numeric) or where(is.character) |
group_cols() |
Select the columns grouped with group_by |
everything() |
Select all columns |
contains
The contains function matches all columns containing a string. In the following example we select all the columns that include “color” in their name.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Select 'name' and all columns containing 'color'
df_2 <- df %>%
select(name, contains("color"))
df_2# A tibble: 5 × 4
name hair_color skin_color eye_color
<chr> <chr> <chr> <chr>
1 Luke Skywalker blond fair blue
2 C-3PO NA gold yellow
3 R2-D2 NA white, blue red
4 Darth Vader none white yellow
5 Leia Organa brown light brown 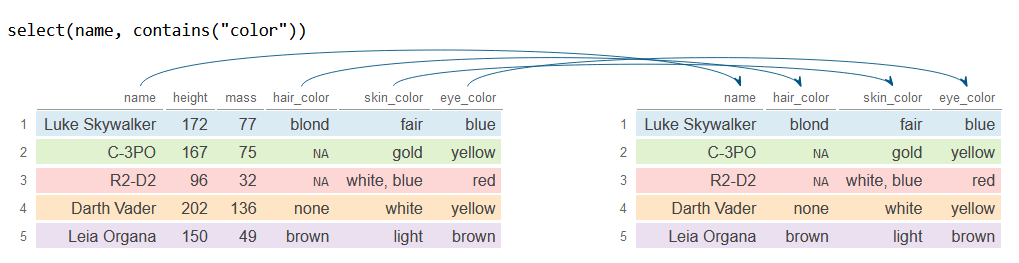
To select columns that does not contain a string use !contains("string") or -contains("string").
all_of and any_of
The all_of and any_of function allow to select columns from character vectors. The difference between these functions is that all_of selects all the columns based on the vector and if any variable is missing an error is thrown, while any_of selects variables based on the vector without checking missing variables.
In the following block of code we are selecting the columns based on a vector named column_names using all_of.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Desired columns
column_names <- c("name", "eye_color")
df_2 <- df %>%
select(name, all_of(column_names))
df_2# A tibble: 5 × 2
name eye_color
<chr> <chr>
1 Luke Skywalker blue
2 C-3PO yellow
3 R2-D2 red
4 Darth Vader yellow
5 Leia Organa brown 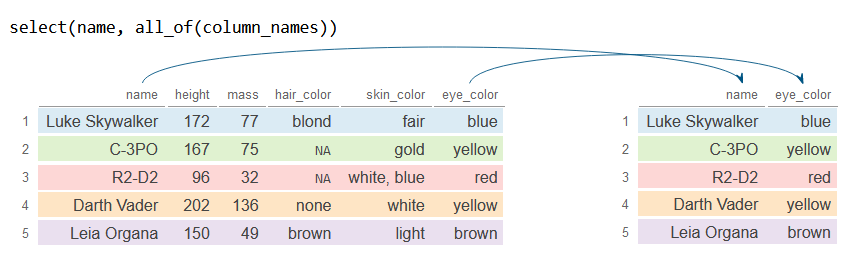
Now we pass another vector in which there are two column names that do not exist, but the any_of function will select those columns that are in the data frame and ignore the others.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Desired columns
column_names <- c("name", "skin_color", "gender", "abc")
df_2 <- df %>%
select(name, any_of(column_names))
df_2# A tibble: 5 × 2
name skin_color
<chr> <chr>
1 Luke Skywalker fair
2 C-3PO gold
3 R2-D2 white, blue
4 Darth Vader white
5 Leia Organa light 
starts_with
If you want to select columns that start with a specific string you can use the starts_with function. In the following example we select the variable name and all variables that start with the letter h.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Selects 'name' and all columns starting with "h"
df_2 <- df %>%
select(name, starts_with("h"))
df_2# A tibble: 5 × 3
name height hair_color
<chr> <int> <chr>
1 Luke Skywalker 172 blond
2 C-3PO 167 NA
3 R2-D2 96 NA
4 Darth Vader 202 none
5 Leia Organa 150 brown 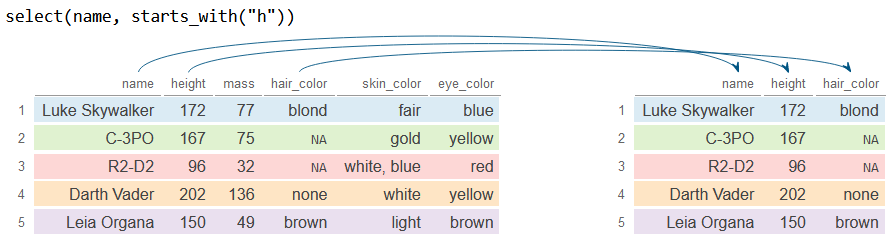
ends_with
Similar to the previous function, ends_with searches for the columns that end with a specific string. The example above we select the first variable (name) and all variables that end with "ss" (mass).
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Selects 'name' and all columns ending in "ss"
df_2 <- df %>%
select(name, ends_with("ss"))
df_2# A tibble: 5 × 2
name mass
<chr> <dbl>
1 Luke Skywalker 77
2 C-3PO 75
3 R2-D2 32
4 Darth Vader 136
5 Leia Organa 49 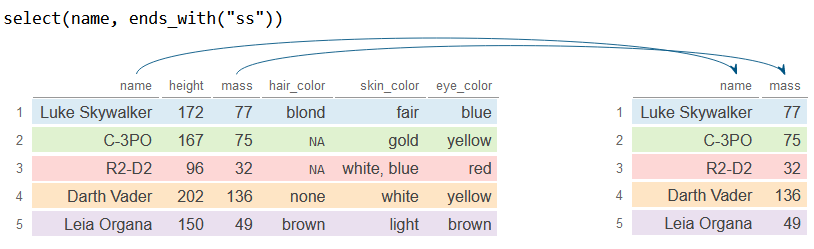
last_col
The last_col function selects the last variable of the data frame. Note that this function provides an argument named offset that defaults to 0 to select the nth variable from the end.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Last column
df_2 <- df %>%
select(name, last_col())
df_2# A tibble: 5 × 2
name eye_color
<chr> <chr>
1 Luke Skywalker blue
2 C-3PO yellow
3 R2-D2 red
4 Darth Vader yellow
5 Leia Organa brown 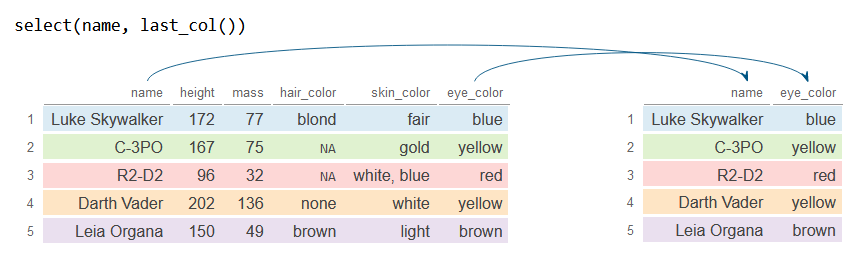
Use !last_col() or -last_col() to select columns until last column.
matches
The matches function selects columns based on regular expressions. The following block of code selects all columns containing the letter a or the letter t.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Columns containing the letter "a" or the letter "t"
df_2 <- df %>%
select(matches("a|t"))
df_2# A tibble: 5 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Luke Skywalker 172 77 blond
2 C-3PO 167 75 NA
3 R2-D2 96 32 NA
4 Darth Vader 202 136 none
5 Leia Organa 150 49 brown 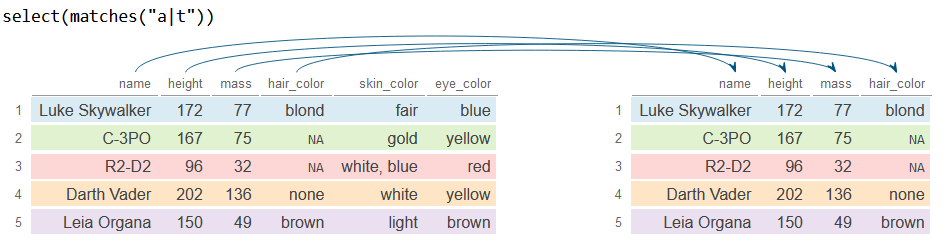
num_range
If your variables are named with a prefix and a numeric range, such as x1, x2, … or y_1, y_2, … you can use the num_range function to quickly select a range of columns.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# New column names
colnames(df) <- paste0("x", 1:ncol(df))
# Selects x1, x2 and x3
df_2 <- df %>%
select(num_range("x", 1:3))
df_2# A tibble: 5 × 3
x1 x2 x3
<chr> <int> <dbl>
1 Luke Skywalker 172 77
2 C-3PO 167 75
3 R2-D2 96 32
4 Darth Vader 202 136
5 Leia Organa 150 49 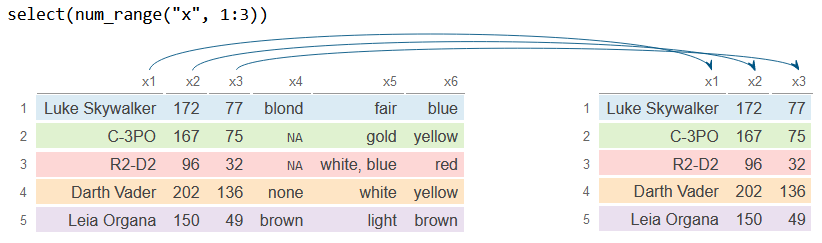
where
The where function takes a function that returns TRUE or FALSE as input and selects columns based on the desired condition. For example, you can select or drop all numeric, character or factor variables using where(is.numeric), where(is.character) and where(is.factor), respectively.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
# Select all character variables
df_2 <- df %>%
select(where(is.character))
df_2# A tibble: 5 × 4
name hair_color skin_color eye_color
<chr> <chr> <chr> <chr>
1 Luke Skywalker blond fair blue
2 C-3PO NA gold yellow
3 R2-D2 NA white, blue red
4 Darth Vader none white yellow
5 Leia Organa brown light brown 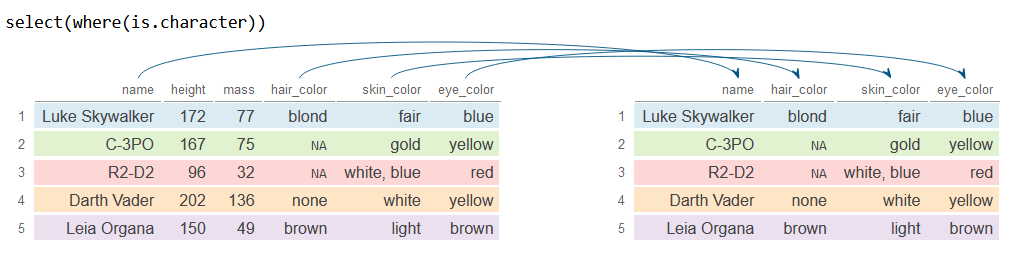
group_cols
The group_cols function selects the previously grouped columns with group_by.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
df_2 <- df %>%
group_by(name, eye_color) %>%
select(group_cols())
df_2# A tibble: 5 × 2
# Groups: name, eye_color [5]
name eye_color
<chr> <chr>
1 Luke Skywalker blue
2 C-3PO yellow
3 R2-D2 red
4 Darth Vader yellow
5 Leia Organa brown 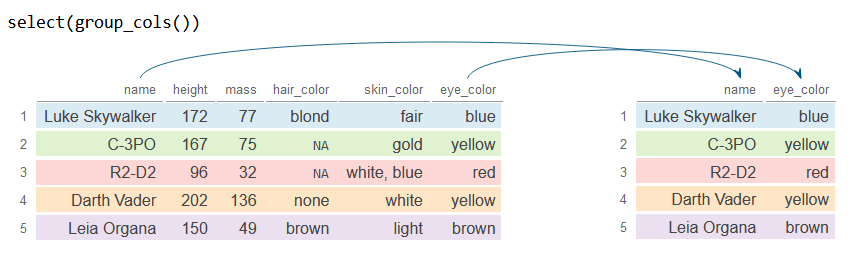
everything
The everything function allows to select all columns. This function is specially useful when combined with other dplyr functions.
# install.packages("dplyr")
library(dplyr)
# Sample data
df <- starwars[1:5, 1:6]
df_2 <- df %>%
select(everything())
df_2# A tibble: 5 × 6
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Luke Skywalker 172 77 blond fair blue
2 C-3PO 167 75 NA gold yellow
3 R2-D2 96 32 NA white, blue red
4 Darth Vader 202 136 none white yellow
5 Leia Organa 150 49 brown light brown 
You can select the intersection or union of two sets of variables with & and |. For instance, select(starts_with("h") & ends_with("r")) selects all columns that starts with the letter hand ends with r.