Merge data frames in R
The R merge function allows merging two data frames by common columns or by row names. This function allows you to perform different database (SQL) joins, like left join, inner join, right join or full join, among others. In this tutorial you will learn how to merge datasets in base R in the possible available ways with several examples.
Merge function in R
The syntax of the R merge function with a brief description of its arguments is shown in the following block of code:
merge(x, y, ...)
# For data frames:
merge(x, y, # Data frames or objects to be coerced
by = intersect(names(x), names(y)), # Columns used for merging
by.x = by, by.y = by, # Columns used for merging
all = FALSE, # If TRUE, all.x = TRUE and all.y = TRUE
all.x = all, all.y = all, # If TRUE, adds rows for each row in x (y) that not match a row in y (x).
sort = TRUE, # Whether to sort the output by the 'by' columns
suffixes = c(".x",".y"), # Suffixes for creating unique column names
no.dups = TRUE, # Whether to avoid duplicated column names appending more suffixes or not
incomparables = NULL, # How to deal with values that can not be matched
...) # Additional argumentsNote that the main method of the R merge function is for data frames. However, merge is a generic function that can be also used with other objects (like vectors or matrices), but they will be coerced to data.frame class.
R merge data frames
In order to create a reproducible example to show how to merge two data frames in R we are going to use the following sample datasets named df_1, that represents the id, name and monthly salary of some employees of a company and df_2, that shows the id, name, age and position of some employees.
set.seed(61)
employee_id <- 1:10
employee_name <- c("Andrew", "Susan", "John", "Joe", "Jack",
"Jacob", "Mary", "Kate", "Jacqueline", "Ivy")
employee_salary <- round(rnorm(10, mean = 1500, sd = 200))
employee_age <- round(rnorm(10, mean = 50, sd = 8))
employee_position <- c("CTO", "CFO", "Administrative", rep("Technician", 7))
df_1 <- data.frame(id = employee_id[1:8], name = employee_name[1:8],
month_salary = employee_salary[1:8])
df_2 <- data.frame(id = employee_id[-5], name = employee_name[-5],
age = employee_age[-5], position = employee_position[-5])
df_1
df_2 # df_1 # df_2
id name month_salary id name age position
1 Andrew 1424 1 Andrew 40 CTO
2 Susan 1425 2 Susan 38 CFO
3 John 1156 3 John 54 Administrative
4 Joe 1570 4 Joe 66 Technician
5 Jack 1223 6 Jacob 38 Technician
6 Jacob 1462 7 Mary 53 Technician
7 Mary 1641 8 Kate 56 Technician
8 Kate 1603 9 Jacqueline 55 Technician
10 Ivy 43 TechnicianNote that on a real life example, all ids will be unique but the names can be repeated. Also note that ‘Jack’ is missing in the second table (neither his age nor his position are available) and ‘Jacqueline’ and ‘Ivy’ are missing in the first (their monthly salaries are not available with the current data).
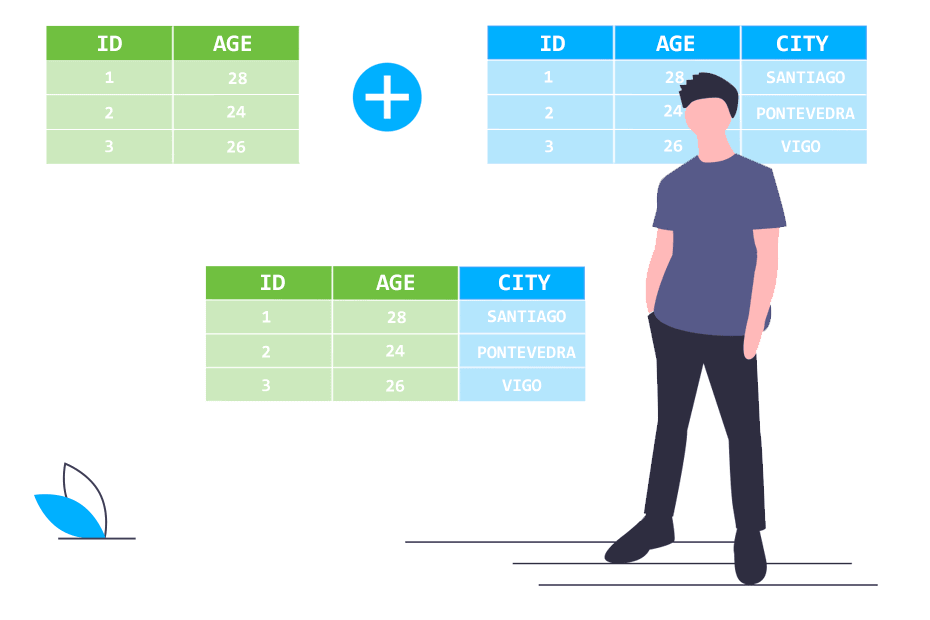
Inner join
An inner join (actually a natural join), is the most usual join of data sets that you can perform. It consists on merging two dataframes in one that contains the common elements of both, as described in the following illustration:
In order to merge the two sample data sets, you just have to pass them to the merge function without the need of changing other arguments, due to by default, the function merges the data sets by the common column names. In consequence, in this case, the function merges the data by two columns (id and name).
merge(x = df_1, y = df_2)
merge(x = df_1, y = df_2, by = c("id", "name")) # Equivalent id name month_salary age position
1 Andrew 1424 40 CTO
2 Susan 1425 38 CFO
3 John 1156 54 Administrative
4 Joe 1570 66 Technician
6 Jacob 1462 38 Technician
7 Mary 1641 53 Technician
8 Kate 1603 56 TechnicianAs we pointed out before, ‘Jack’, ‘Ivy’ and ‘Jacqueline’ were not in both tables. In consequence, in the resulting output of this join they are missing.
Full (outer) join
The outer join, also known as full outer join or full join, merges all the columns of both data sets into one for all elements:
In order to create a full outer join of the two data frames in R you have to set the argument all to TRUE:
merge(x = df_1, y = df_2, all = TRUE) id name month_salary age position
1 Andrew 1424 40 CTO
2 Susan 1425 38 CFO
3 John 1156 54 Administrative
4 Joe 1570 66 Technician
5 Jack 1223 NA <NA> # <-- NA values
6 Jacob 1462 38 Technician
7 Mary 1641 53 Technician
8 Kate 1603 56 Technician
9 Jacqueline NA 55 Technician # <-- NA value
10 Ivy NA 43 Technician # <-- NA valueAs not all rows in the first data frame match all the rows in the second, the output is filled with NA values in those cases.
Left (outer) join in R
The left join in R consist on matching all the rows in the first data frame with the corresponding values on the second. Recall that ‘Jack’ was on the first table but not on the second.
In order to create the join, you just have to set all.x = TRUE as follows:
merge(x = df_1, y = df_2, all.x = TRUE) id name month_salary age position
1 Andrew 1424 40 CTO
2 Susan 1425 38 CFO
3 John 1156 54 Administrative
4 Joe 1570 66 Technician
5 Jack 1223 NA <NA> # <-- NA values
6 Jacob 1462 38 Technician
7 Mary 1641 53 Technician
8 Kate 603 56 TechnicianAs the employee corresponding to id = 5 is on the first data set but not on the second, the corresponding missing values are displayed as NA.
Right (outer) join in R
The right join in R is the opposite of the left outer join. In this case, the merge consists on joining all the rows in the second data frame with the corresponding on the first.
In consequence, you will need to set the argument all.y to TRUE to join the datasets this way.
merge(x = df_1, y = df_2, all.y = TRUE) id name month_salary age position
1 Andrew 1424 40 CTO
2 Susan 1425 38 CFO
3 John 1156 54 Administrative
4 Joe 1570 66 Technician
6 Jacob 1462 38 Technician
7 Mary 1641 53 Technician
8 Kate 1603 56 Technician
9 Jacqueline NA 55 Technician # <-- Note the difference
10 Ivy NA 43 Technician # <-- with the left joinAs ‘Jacqueline’ and ‘ Ivy’ are on the second data set but not on the first, the corresponding values of monthly salary are not available.
Cross join
The R cross join performs the Cartesian product of the datasets df_1 and df_2:
You can create a cross join in R setting as NULL the argument by of the R merge function. Note that we only show the first rows of the output, as it is very large.
Merged <- merge(x = df_1, y = df_2, by = NULL)
head(Merged) id.x name.x month_salary id.y name.y age position
1 Andrew 1424 1 Andrew 40 CTO
2 Susan 1425 1 Andrew 40 CTO
3 John 1156 1 Andrew 40 CTO
4 Joe 1570 1 Andrew 40 CTO
5 Jack 1223 1 Andrew 40 CTO
6 Jacob 1462 1 Andrew 40 CTOMerge rows in R
You can also merge data frames by row names. For illustration purposes, consider the following datasets:
df1 <- data.frame(var = c("one", "two", "three", "four", "five"),
data = c(1, 5, 1, 6, 8))
rownames(df1) <- c("A", "B", "C", "D", "E")
df1
df2 <- data.frame(var = c("three", "one", "eight", "two", "nine"),
data = c(1, 5, 1, 6, 8))
rownames(df2) <- c("E", "A", "B", "D", "C")
df2# df1 # df2
var data var data
A one 1 E three 1
B two 5 A one 5
C three 1 B eight 1
D four 6 D two 6
E five 8 C nine 8In this case, in order to join the data frames by the row names you have to set the argument by to 0 or to "row.names".
merge(df1, df2, by = 0, all = TRUE)
merge(df1, df2, by = "row.names", all = TRUE) # Equivalent Row.names var.x data.x var.y data.y
1 A one 1 one 5
2 B two 5 eight 1
3 C three 1 nine 8
4 D four 6 two 6
5 E five 8 three 1As you can observe, the output contains as many rows as different row names. Note that we applied a full outer join (as in this case it is equivalent to a left and right join), but you could join the data as you want.
Merge more than two dataframes in R
Finally, it is worth to mention that you can iteratively merge data frames in R, concatenating the merge function. Consider, for instance the following data frames:
x <- data.frame(id = 1:4, year = 1995:1998)
x
y <- data.frame(id = c(4, 1, 3, 2),
year = c(1998, 1995, 1997, 1996), age = c(22, 25, 23, 24))
y
z <- data.frame(id = c(1, 2, 3), year = 1995:1997, wage = c(1000, 1200, 1599))
z# x # y # z
id year id year age id year wage
1 1995 4 1998 22 1 1995 1000
2 1996 1 1995 25 2 1996 1200
3 1997 3 1997 23 3 1997 1599
4 1998 2 1996 24You can merge the three data frames merging two and then merging the output with the remaining data set.
merge(x, merge(y, z))id year age wage
1 1995 25 1000
2 1996 24 1200
3 1997 23 1599Note that you can specify the arguments you prefer for each join and that you can concatenate as many merges as you need.
merge(x, merge(y, z, all = TRUE), all = TRUE)id year age wage
1 1995 25 1000
2 1996 24 1200
3 1997 23 1599
4 1998 22 NAA cleaner alternative is to use the Reduce function as follows, so instead of concatenating the merge functions, you can specify all the data frames inside a list. Nonetheless, you will have to specify the same arguments for all joins.
Reduce(function(x, y) merge(x, y), list(x, y, z))id year age wage
1 1995 25 1000
2 1996 24 1200
3 1997 23 1599