Bucles for en R

El bucle for en R, también conocido como ciclo for, es una iteración repetitiva (en bucle) de cualquier código, donde en cada iteración se evalúa un mismo código a través de los elementos de un vector o lista.
Sintaxis del bucle for en R
La sintaxis del bucle for en R es muy simple:
for (i in lista) {
# Código
}También puedes escribir un bucle for en una sola línea de código sin corchetes. Sin embargo, no es recomendable escribir así los bucles for.
for (i in lista) # CódigoComo primer ejemplo, podrías pensar en imprimir i + 1, siendo i = 1, ..., 5 en cada iteración del bucle. En este caso, el bucle for comenzará con i = 1 y finalizará con i = 5, por lo tanto la salida será la que se muestra a continuación:
for (i in 1:5) {
print(i + 1)
}
# Equivalente a :
# for (i in 1:5) print (i + 1) 2
3
4
5
6Ten en cuenta que ‘i’ toma su valor correspondiente en cada iteración. Cabe destacar también que puedes usar cualquier letra o cadena de caracteres en lugar de ‘i’. Sin embargo, usar ‘i’ es la forma más común de representar la iteración actual en un único bucle.
Bucles for anidados en R
También puedes escribir sentencias for dentro de otras. A esto se le llama bucles anidados. La sintaxis se representa en el siguiente bloque de código:
for (i in lista) {
# Código
for(j in lista) {
# Código
}
}Asegúrate de cambiar el nombre que le das a los índices cuando trabajes con bucles anidados. Nunca uses el mismo nombre para los índices dos veces.
Ejemplos del ciclo for en R
Bootstrap con el bucle for
Supón que quieres conocer la media muestral de n observaciones obtenidas independientemente de una distribución uniforme a lo largo del intervalo (0, 1). El problema mencionado se puede resolver teóricamente, pero vamos a realizar una simulación. Para ese propósito, debemos seguir estos simples pasos:
- Generar n observaciones con distribución uniforme en (0, 1).
- Calcular la media muestral de los datos.
- Repetir los pasos anteriores un elevado número de repeticiones.
- Aproximar la distribución de la media muestral con el histograma obtenido con las medias muestrales obtenidas en las repeticiones.
Si estás familiarizado con los métodos estadísticos, puede que te hayas dado cuenta de que estamos ejecutando un bootstrap uniforme.
set.seed(1) # Fijamos semilla para reproductibilidad
rep <- 50000 # Número de repeticiones
n <- 2 # Número de puntos
Mean <- numeric(rep)
for (irep in 1:rep) {
x <- runif(n)
Mean[irep] <- mean(x)
}
hist(Mean, breaks = 40, main = paste("n = ", n))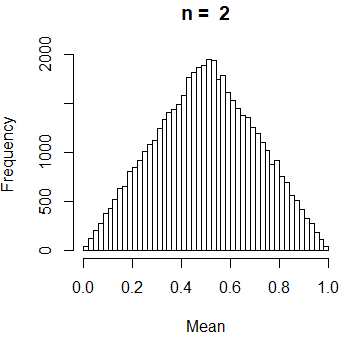
Creando un reloj con el bucle for
Ahora vamos a representar un minuto en segundos de reloj. Esta animación es recomendable que la hagas en R base en lugar de en RStudio, ya que la tasa de refresco de los gráficos en R GUI es menor.
angulo <- seq(0, 360, length = 60)
radianes <- angulo * pi / 180
x <- cos(radianes)
y <- sin(radianes)
for (i in 1:60) {
plot(y, x, axes = F, xlab = "", ylab = "", type = "l", col = "grey")
arrows(0, 0, y[i], x[i], col = "blue")
Sys.sleep(1) # Espera un segundo
}En cada iteración, el bucle anterior dibuja un reloj y después de un segundo dibuja el segundo siguiente y así sucesivamente. La representación de una iteración se muestra en la siguiente imagen:

Las funciones break y next
A veces es necesario detener el ciclo en algún índice si se cumple alguna condición o evitar evaluar algún código para algún índice o condición. Para ese propósito puedes usar las funciones break y next.
En el siguiente ejemplo, el bucle se interrumpirá en la sexta iteración (que ya no será evaluada) a pesar de que el ciclo completo tiene 15 iteraciones, y además se saltará la tercera iteración.
for (iter in 1:15) {
if (iter == 3) {
next
}
if (iter == 6) {
break
}
print(iter)
}1
2
4
5Preasignar espacio para ejecutar bucles
Los bucles son especialmente lentos en R. Si ejecutas o planeas ejecutar tareas computacionalmente costosas, debes preasignar memoria. Esta técnica consiste en reservar espacio para los objetos que estás creando o rellenando dentro de un bucle. Veamos un ejemplo.
Primero, puedes crear una variable llamada almacenar sin indicar el tamaño de la variable final una vez que se haya llenado dentro del bucle. La función Sys.time almacenará la hora exacta en el que se ejecuta la función en sí, así que asegúrate de llamar al siguiente código de una vez, no línea por línea.
inicio <- Sys.time()
almacenar <- numeric() # Sin preasignación
for (i in 1:1000000){
almacenar[i] <- i ** 2
}
fin <- Sys.time()
fin - inicio # El código tardó en ejecutarse 0.4400518 segundos en mi ordenadorSegundo, copia el código anterior y preasigna la variable almacenar con la longitud final que tendrá el vector.
inicio <- Sys.time()
almacenar <- numeric(1000000) # Con preasignación
for (i in 1:1000000){
almacenar[i] <- i ** 2
}
fin <- Sys.time()
fin - inicio # El código tardó en ejecutarse 0.126972 segundos¡Casi 3.5 veces más rápido!
Ten en cuenta que los resultados pueden depender de la velocidad de tu ordenador y variarán si ejecutas el código varias veces. Sin embargo, cuantos más recursos consuman la tarea, mayor será la reducción de tiempo de ejecución si preasignas espacio para los objectos en la memoria. Si intentas ejecutar los códigos anteriores para solo 1000 o 10000 iteraciones, no verás prácticamente ninguna diferencia.
Bucle for vectorizado
La función foreach es una alternativa del bucle for del paquete foreach. Sin embargo, esta función es similar a la función apply. Ten en cuenta que también necesitarás usar el operador %do%. Esta función puede hacer que tus bucles sean más rápidos, pero la velocidad final podría depender del bucle que realices.
En el siguiente ejemplo creamos una función llamada for_each donde ejecutamos la raíz cuadrada del valor correspondiente de cada iteración. Como foreach devuelve una lista de forma predeterminada, puedes usar el argumento .combine y establecerlo como 'c' para que la salida se concatene. Otra opción es devolver el resultado envuelto por la función unlist.
# install.packages("foreach")
library(foreach)
for_each <- function(x) {
res <- foreach(i = 1:x, .combine = 'c') %do% {
sqrt(i)
}
return(res)
}
for_each(10)1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 2.645751 2.828427 3.000000 3.162278Bucle for con proceso en paralelo
Cuando se trata de tareas computacionalmente muy intensivas, como estudios de simulación, puede que necesites hacer que tus bucles sean paralelos. Para eso necesitarás hacer uso de los paquetes parallel y doParallel. Sin embargo, el segundo paquete se carga cuando carga el primero, por lo que no necesitas cargar ambos.
En el siguiente ejemplo, configuramos nuestra ejecución paralela con todos los núcleos disponibles, pero puedes usar tantos como quieras. Luego registramos la paralelización y al acabar, debes recordar detener el clúster.
Nótese que necesitas usar %dopar% en lugar de %do%.
library(parallel)
par_for_each <- function(x) {
cl <- parallel::makeCluster(detectCores())
doParallel::registerDoParallel(cl)
res <- foreach(i = 1:x, .combine = 'c') %dopar% {
sqrt(i)
}
parallel::stopCluster(cl)
return(res)
}
par_for_each(10)1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 2.645751 2.828427 3.000000 3.162278Los bucles en paralelo necesitan cierto tiempo para registrar el entorno en paralelo. Por tanto, solo son más eficientes con ciclos for muy intensivos desde el punto de vista computacional.