Muestras aleatorias y permutaciones en R con sample()
La función sample de R se utiliza para generar muestras aleatorias o permutaciones (muestras con o sin reemplazamiento) e incluso seleccionar elementos aleatoriamente en función de probabilidades específicas asignadas a cada elemento (muestreo ponderado).
Si ejecutas los ejemplos de este tutorial obtendrás otros resultados. Establece una semilla con set.seed para que los resultados sean reproducibles.
Sintaxis de la función sample
La función sample se compone de cuatro argumentos:
sample(x, size, replace = FALSE, prob = NULL)Siendo:
x: un vector o lista que contiene los elementos entre los que seleccionar una muestra.size: el número de elementos a seleccionar. Sireplace = TRUE, especifica el número de elementos a muestrear con reemplazo.replace: un valor lógico que indica si el muestreo debe realizarse con reemplazo (TRUE) o sin reemplazo (FALSE). Por defecto esFALSE.prob: un vector opcional de pesos de probabilidad para obtener los elementos dex.
Muestreo aleatorio sin reemplazo
Por defecto, la función sample devuelve una permutación aleatoria del vector de entrada, es decir, devuelve los elementos del vector pero en un orden diferente (sin repetir ninguno). El siguiente ejemplo ilustra cómo la función devuelve el vector llamado x pero en uno de los posibles órdenes diferentes.
x <- 1:10
# Permutación de 'x'
sample(x)2 3 10 7 5 9 4 6 1 8Ten en cuenta que también puedes utilizar la función sample con vectores de caracteres o lógicos e incluso listas.
y <- c("A", "A", "C", "D")
# Permutación de 'y'
sample(y)"D" "C" "A" "A"Con size puedes controlar la longitud del resultado. El siguiente ejemplo ilustra cómo devolver sólo una muestra, es decir, 1 de los 10 elementos del vector de entrada.
x <- 1:10
# Una muestra
sample(x, size = 1)3Observa que no puedes introducir un valor mayor que la longitud del vector de entrada. En este caso, se producirá un error a menos que establezcas replace = TRUE.
x <- 1:10
# 'size' no puede ser mayor a la longitud de 'x'
sample(x, size = 15)Error in sample.int(length(x), size, replace, prob) :
cannot take a sample larger than the population when 'replace = FALSE'Muestreo aleatorio con reemplazo
Cuando replace = TRUE el muestreo se realiza con reemplazo, por lo que si un elemento es elegido también puede serlo en el siguiente muestreo y el mismo elemento puede aparecer varias veces.
x <- 1:10
# Muestra aleatoria con reemplazo
sample(x, replace = TRUE)5 2 4 6 7 6 3 7 10 1En este caso, el tamaño de la muestra puede ser mayor que la longitud del vector de entrada y los elementos pueden repetirse.
x <- 1:10
# Muestra aleatoria
sample(x, size = 15, replace = TRUE)2 7 4 3 1 7 2 4 4 3 10 7 2 5 3Muestreo ponderado
Cuando se calcula una muestra aleatoria, todos los elementos tienen la misma probabilidad. Esto se puede ilustrar con un gráfico de barras con las proporciones de una muestra aleatoria de un vector con dos elementos diferentes.
set.seed(21)
tab <- table(sample(c("A", "B"), size = 10000, replace = TRUE))
# Gráfico de barras con proporciones
barplot(prop.table(tab), col = c(4, 3), main = "Muestreo aleatorio")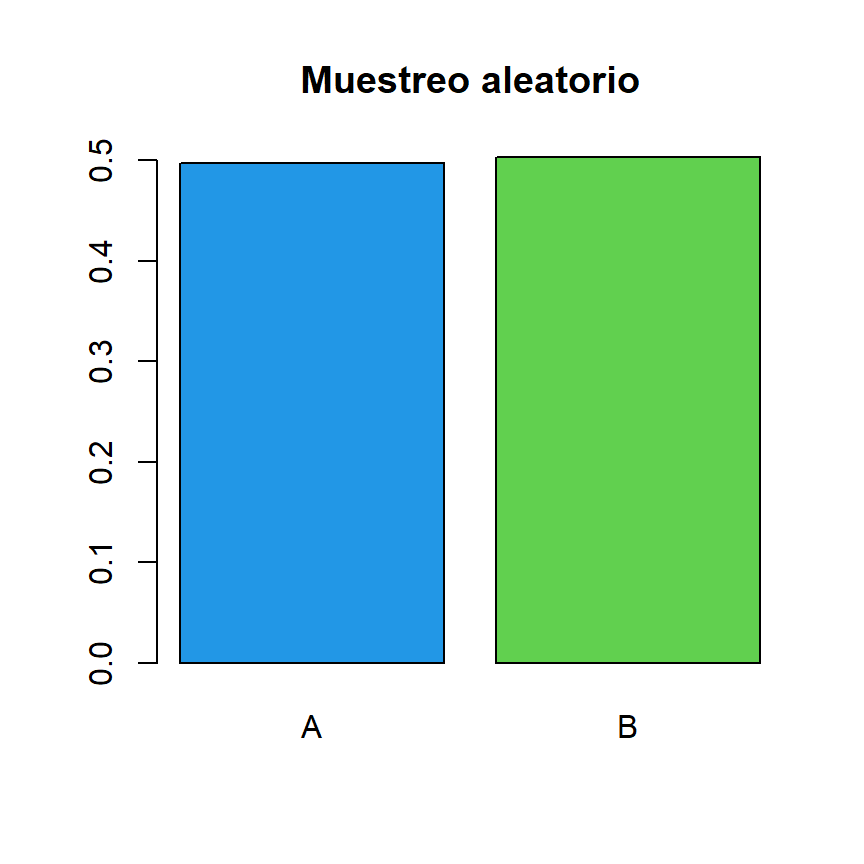
Sin embargo, el argumento prob permite especificar diferentes probabilidades para cada elemento para reflejar escenarios del mundo real. En el siguiente ejemplo, el primer elemento del vector tendrá una probabilidad de 0.8 mientras que el segundo de 0.2.
# Muestreo ponderado
sample(c("A", "B"), size = 10, prob = c(0.8, 0.2), replace = TRUE)"A" "B" "B" "A" "A" "A" "A" "A" "A" "A"Las proporciones de los elementos de la salida serán (como en este ejemplo) o estarán próximas a las probabilidades especificadas.
tab <- table(c("A", "B", "B", "A", "A", "A", "A", "A", "A", "A"))
# Gráfico de barras con proporciones
barplot(prop.table(tab), col = c(4, 3), main = "Muestreo ponderado")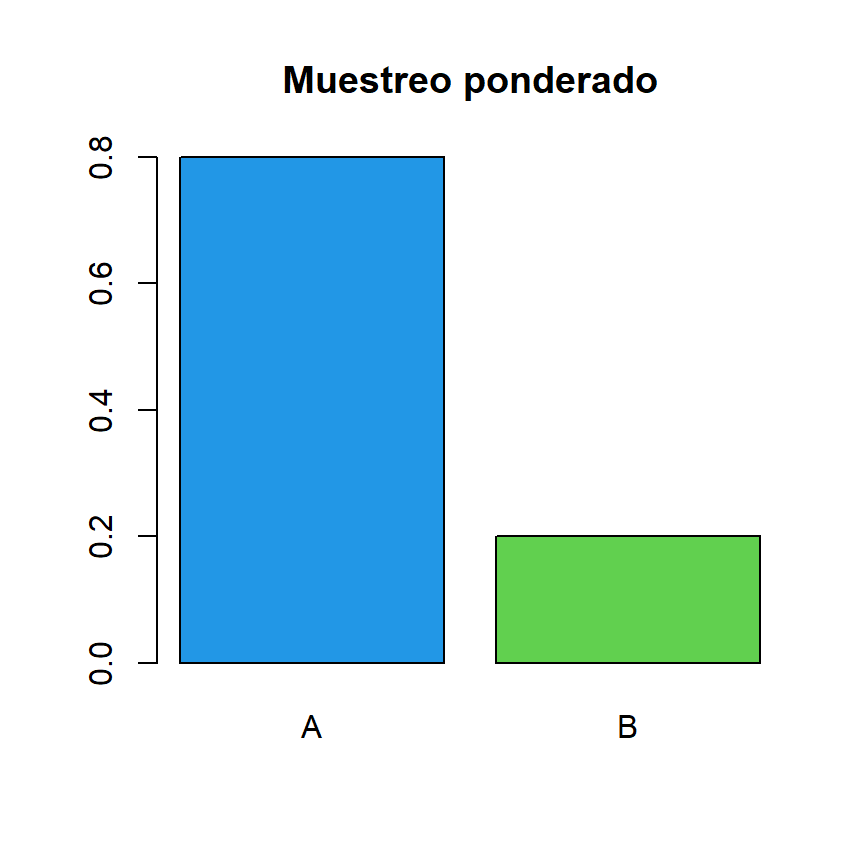
Observa que las proporciones de los elementos de la salida convergerán a las probabilidades especificadas a medida que aumente el tamaño de la muestra. El siguiente bloque de código crea un gráfico de líneas para ilustrar esta convergencia.
# Tamaños muestrales
s <- seq(5, 10000, 5)
# Data frame vacío
df <- data.frame("A" = NA, "B" = NA)
# Calcula muestras para distintos tamaños muestrales
set.seed(2)
for(i in 1:length(s)) {
a <- sample(c("A", "B"), size = i, replace = TRUE, prob = c(0.2, 0.8))
df[i, ] <- prop.table(table(a))
}
# Gráfico de líneas
plot(s, df$A, type = "l", xlab = "Tamaño muestral", ylab = "%")
lines(s, df$B, type = "l", col = 4)
abline(h = 0.8, lty = 2, col = "red")
abline(h = 0.2, lty = 2, col = "red")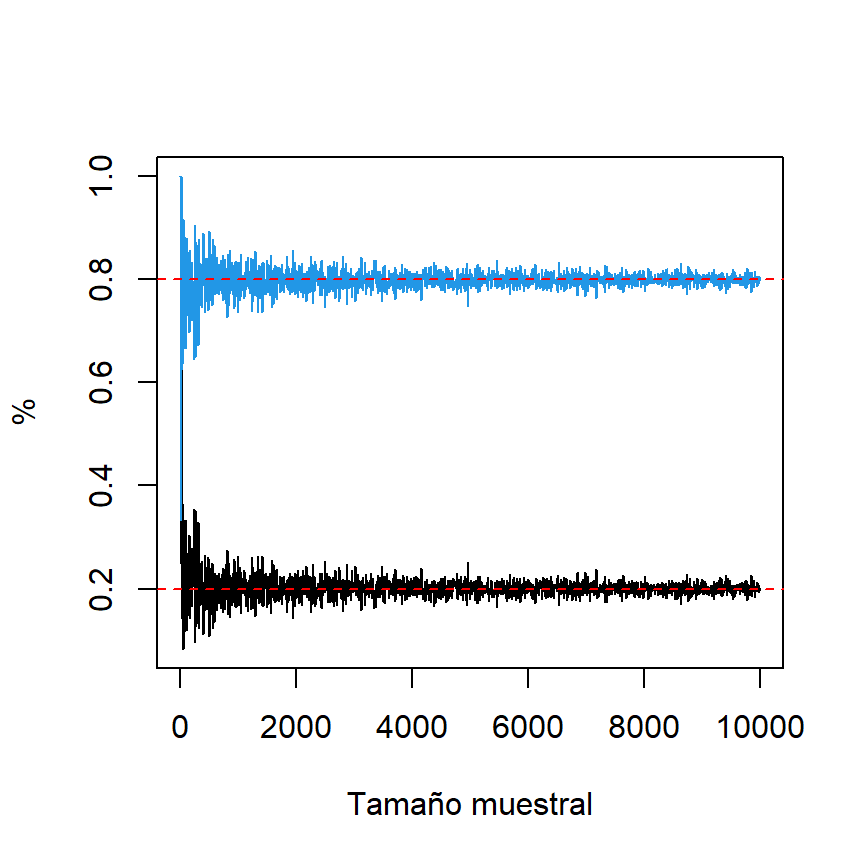
Ejemplos adicionales
Muestras reproducibles
Como se ha dicho antes, si no se establece una semilla, los resultados no serán reproducibles. La función set.seed permite especificar una semilla para la generación de números pseudoaleatorios y así hacer reproducible la salida.
# Fija una semilla (cualquier entero)
set.seed(1)
# Muestra reproducible
sample(1:10)9 4 7 1 2 5 3 10 6 8Si ejecutas el código anterior obtendrás la misma salida del bloque de código.
Muestra aleatoria de un data frame
Un caso de uso habitual de la función sample es seleccionar aleatoriamente filas de un data frame. Como las filas en R se pueden seleccionar utilizando índices, puedes crear una muestra del tamaño deseado de un vector desde 1 al número de filas para crear una muestra de filas.
# Datos de ejemplo
set.seed(21)
df <- data.frame(x = 1:10, y = rnorm(10))
# Seleccionamos 5 filas de manera aleatoria
df[sample(1:nrow(df), size = 5), ] x y
10 10 -0.002393336
1 1 0.793013171
2 2 0.522251264
7 7 -1.570199630
8 8 -0.934905667