Seleccionar columnas en R con dplyr
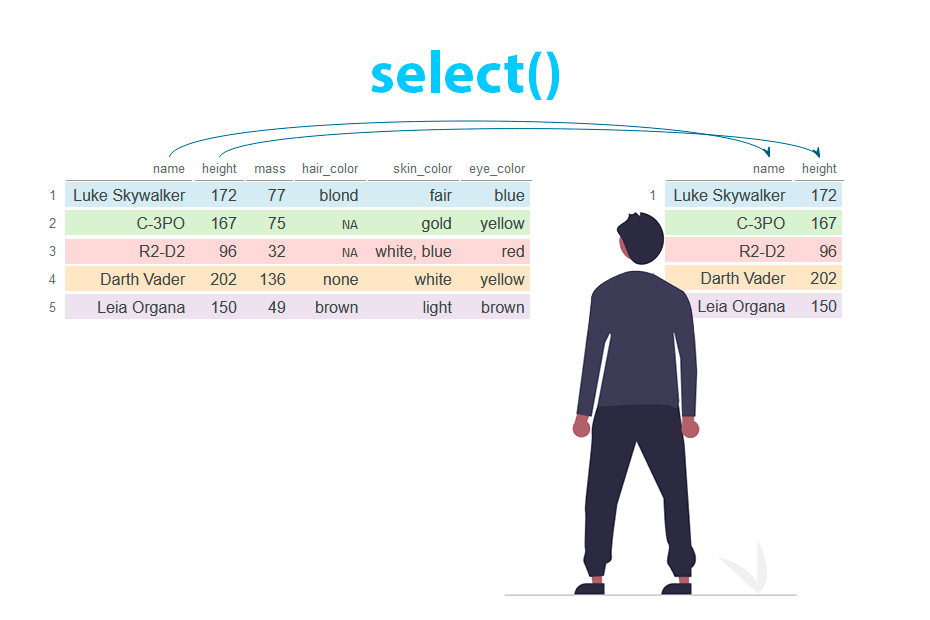
Selecciona o elimina columnas de un data frame con la función select de dplyr y aprende a usar funciones de ayuda para seleccionar columnas como contains, matches, all_of, any_of, starts_with, ends_with, last_col, where, num_range y everything.
Datos de ejemplo para este tutorial
En este tutorial utilizaremos como datos de ejemplo las cinco primeras filas y las seis primeras columnas del conjunto de datos starwars de dplyr.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Vemos los datos
df# A tibble: 5 × 6
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Luke Skywalker 172 77 blond fair blue
2 C-3PO 167 75 NA gold yellow
3 R2-D2 96 32 NA white, blue red
4 Darth Vader 202 136 none white yellow
5 Leia Organa 150 49 brown light brown Seleccionar columnas
La función select permite filtrar columnas de un data frame. Las columnas pueden seleccionarse por nombre o por índice/posición.
Por nombre
Dado un conjunto de datos, tendrás que especificar las columnas deseadas dentro de select con o sin comillas. Ten en cuenta que puedes seleccionar una o varias columnas a la vez.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Selecciona las columnas 'name' y 'height'
df_2 <- df %>%
select(name, height) # O select(c("name", "height"))
df_2# A tibble: 6 × 2
name height
<chr> <int>
1 Luke Skywalker 172
2 C-3PO 167
3 R2-D2 96
4 Darth Vader 202
5 Leia Organa 150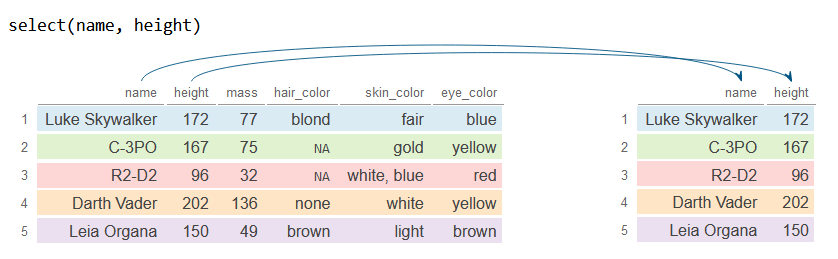
También puedes seleccionar una secuencia de columnas utilizando :. Por ejemplo, si quieres seleccionar las columnas desde height hasta skin_color, ambas incluidas, puedes escribir: height:skin_color
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Selecciona las columnas desde 'height' hasta 'skin_color'
df_2 <- df %>%
select(height:skin_color)
df_2# A tibble: 5 × 4
height mass hair_color skin_color
<int> <dbl> <chr> <chr>
1 172 77 blond fair
2 167 75 NA gold
3 96 32 NA white, blue
4 202 136 none white
5 150 49 brown light 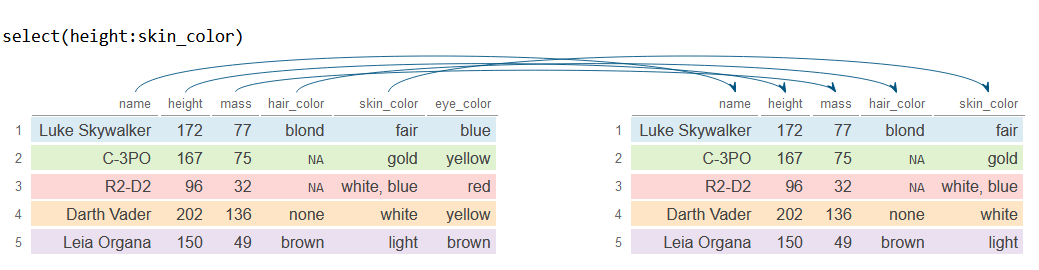
Por índice
Las columnas también se pueden seleccionar por índice. Para ello basta con especificar los números de columna deseados dentro de select. El siguiente ejemplo selecciona la primera, la quinta y la sexta columna.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Selecciona la primera, quinta y sexta columna
df_2 <- df %>%
select(1, 5, 6)
df_2# A tibble: 5 × 3
name skin_color eye_color
<chr> <chr> <chr>
1 Luke Skywalker fair blue
2 C-3PO gold yellow
3 R2-D2 white, blue red
4 Darth Vader white yellow
5 Leia Organa light brown 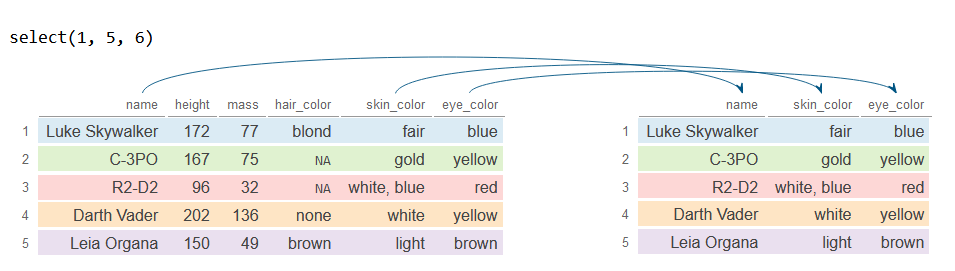
Además, puedes crear una secuencia de números para seleccionar un rango de columnas. El ejemplo siguiente se puede utilizar para seleccionar las primeras n columnas.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Primeras 4 columnas
n <- 4
# Selecciona las primeras 4 columnas
df_2 <- df %>%
select(1:n)
df_2# A tibble: 5 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Luke Skywalker 172 77 blond
2 C-3PO 167 75 NA
3 R2-D2 96 32 NA
4 Darth Vader 202 136 none
5 Leia Organa 150 49 brown 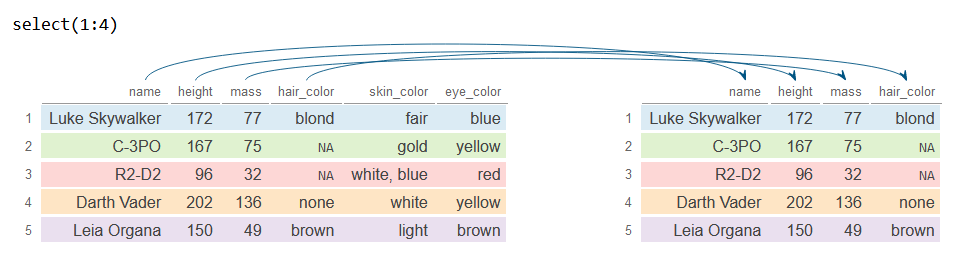
Eliminar columnas
La función select también puede utilizarse para deseleccionar columnas. Para ello, sólo es necesario añadir el símbolo - antes del nombre de cada columna. En el siguiente ejemplo seleccionamos todas las columnas excepto mass.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Selecciona todas las columnas menos 'mass'
df_2 <- df %>%
select(-mass)
df_2# A tibble: 5 × 5
name height hair_color skin_color eye_color
<chr> <int> <chr> <chr> <chr>
1 Luke Skywalker 172 blond fair blue
2 C-3PO 167 NA gold yellow
3 R2-D2 96 NA white, blue red
4 Darth Vader 202 none white yellow
5 Leia Organa 150 brown light brown 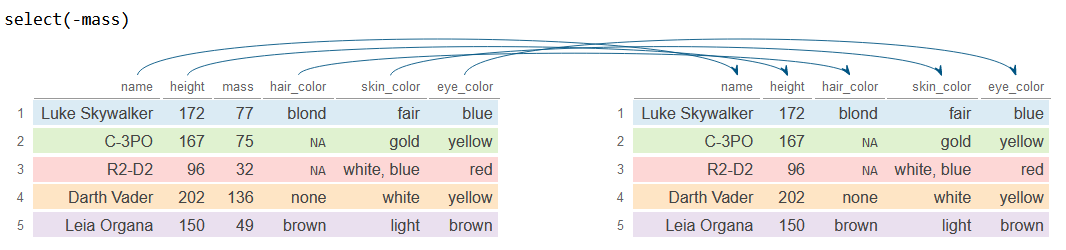
En caso de que quieras eliminar varias columnas puedes añadir - antes del nombre de cada columna o antes de un vector con los nombres.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Eliminamos 'height', 'mass' y 'hair_color'
df_2 <- df %>%
select(-height, -mass, -hair_color) # O -c(height, mass, hair_color)
df_2# A tibble: 5 × 3
name skin_color eye_color
<chr> <chr> <chr>
1 Luke Skywalker fair blue
2 C-3PO gold yellow
3 R2-D2 white, blue red
4 Darth Vader white yellow
5 Leia Organa light brown 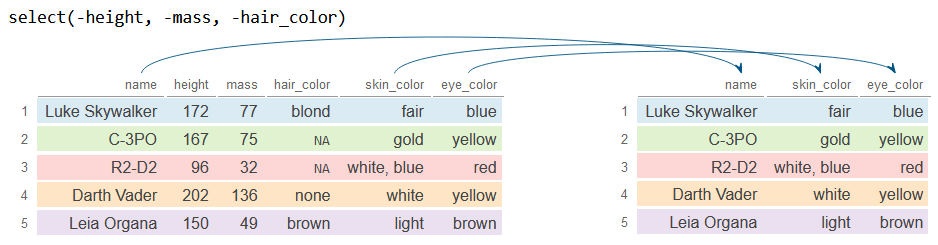
Para eliminar un rango de columnas tendrás que utilizar el operador - y añadir la secuencia de columnas dentro de paréntesis, como en el ejemplo siguiente.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Seleccionar todas las columnas excepto la cuarta, la quinta y la sexta
df_2 <- df %>%
select(-(4:6))
df_2# A tibble: 5 × 3
name height mass
<chr> <int> <dbl>
1 Luke Skywalker 172 77
2 C-3PO 167 75
3 R2-D2 96 32
4 Darth Vader 202 136
5 Leia Organa 150 49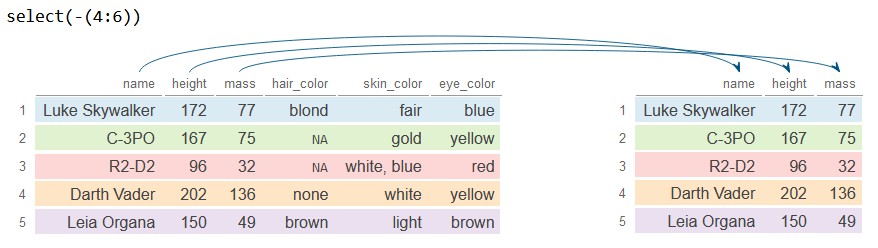
Operador de exclamación
Ten en cuenta que además del operador menos (-) existe el operador de exclamación (!), que niega los criterios de selección. Esto significa que selecciona todas las columnas y excluye las que coinciden con los criterios de selección.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Selecciona TODO menos "name"
df_2 <- df %>%
select(!name)
df_2# A tibble: 5 × 5
height mass hair_color skin_color eye_color
<int> <dbl> <chr> <chr> <chr>
1 172 77 blond fair blue
2 167 75 NA gold yellow
3 96 32 NA white, blue red
4 202 136 none white yellow
5 150 49 brown light brown No confundas el símbolo menos (-) con el signo de exclamación (!). Aunque ambos operadores se utilizan para excluir columnas en la función select de dplyr, el operador - especifica explícitamente las columnas a eliminar, mientras que el operador ! selecciona TODAS las columnas EXCEPTO las que coinciden con los criterios especificados.
Funciones de ayuda para seleccionar o eliminar columnas
Existen varias funciones de ayuda para seleccionar columnas basándose en patrones, como contains, starts_with, ends_with, matches y num_range, basándose en una condición con where, basándose en vectores de caracteres como any_of y all_of, etc. La siguiente tabla describe las funciones más comunes y su uso.
| Función | Descripción |
|---|---|
contains("texto") |
Selecciona columnas que contienen el texto dado |
all_of(c("col1", "col2")) |
Selecciona todas columnas en base a un vector de caracteres |
any_of(c("col1", "col2")) |
Selecciona columnas en base a un vector de caracteres, aunque algunas no existan |
starts_with("prefijo") |
Selecciona columnas que comienzan con el prefijo dado |
ends_with("suffijo") |
Selecciona columnas que terminan con el sufijo dado |
last_col() |
Selecciona la última columna |
matches("regex") |
Selecciona columnas que coinciden con una expresión regular |
num_range("prefijo", 1:5) |
Selecciona columnas con un prefijo y un rango numérico en sus nombres |
where() |
Selecciona columnas que cumplen con una condición dada, e.g. where(is.numeric) o where(is.character) |
group_cols() |
Selecciona las columnas agrupadas con group_by |
everything() |
Selecciona todas las columnas |
contains
La función contains busca todas las columnas que contienen una cadena de texto concreta. En el siguiente ejemplo seleccionamos todas las columnas que incluyen “color” en su nombre.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Selecciona 'name' y las columnas que contienen 'color'
df_2 <- df %>%
select(name, contains("color"))
df_2# A tibble: 5 × 4
name hair_color skin_color eye_color
<chr> <chr> <chr> <chr>
1 Luke Skywalker blond fair blue
2 C-3PO NA gold yellow
3 R2-D2 NA white, blue red
4 Darth Vader none white yellow
5 Leia Organa brown light brown 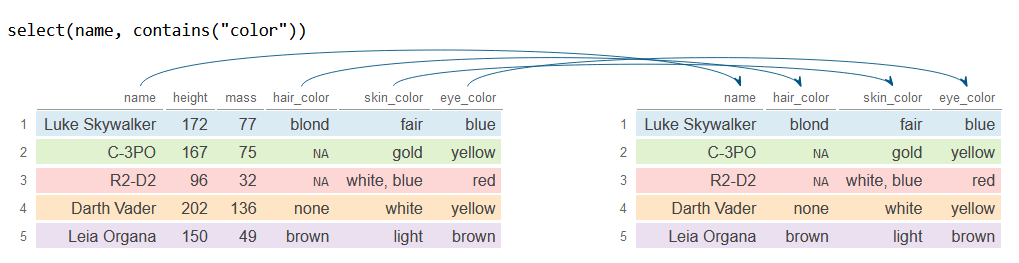
Para seleccionar columnas que no contengan una cadena de texto utiliza !contains("texto") o -contains("texto").
all_of y any_of
Las funciones all_of y any_of permiten seleccionar columnas a partir de vectores de caracteres. La diferencia entre estas funciones es que all_of selecciona todas las columnas basándose en el vector y si falta alguna variable se muestra un error, mientras que any_of selecciona variables basándose en el vector sin comprobar las variables que faltan.
En el siguiente bloque de código estamos seleccionando las columnas basándonos en un vector llamado nombres_columnas usando all_of.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Columnas elegidas
nombres_columnas <- c("name", "eye_color")
df_2 <- df %>%
select(all_of(nombres_columnas))
df_2# A tibble: 5 × 2
name eye_color
<chr> <chr>
1 Luke Skywalker blue
2 C-3PO yellow
3 R2-D2 red
4 Darth Vader yellow
5 Leia Organa brown 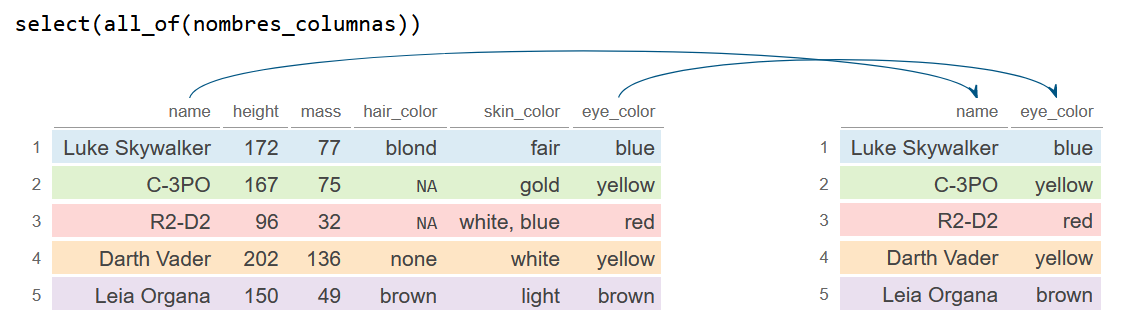
Ahora pasamos otro vector en el que hay dos nombres de columnas que no existen, pero la función any_of seleccionará aquellas columnas que sí se encuentran en el data frame e ignorará las demás.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Columnas elegidas
nombres_columnas <- c("name", "skin_color", "gender", "abc")
df_2 <- df %>%
select(any_of(nombres_columnas))
df_2# A tibble: 5 × 2
name skin_color
<chr> <chr>
1 Luke Skywalker fair
2 C-3PO gold
3 R2-D2 white, blue
4 Darth Vader white
5 Leia Organa light 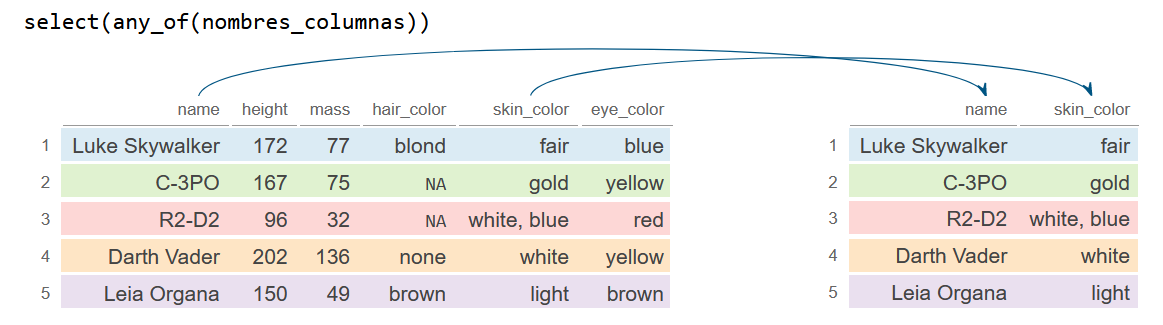
starts_with
Si quieres seleccionar columnas que empiecen por una cadena de texto concreta puedes utilizar la función starts_with. En el siguiente ejemplo seleccionamos la variable name y todas las variables que empiecen por la letra h.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Selecciona 'name' y las columnas que empiezan por "h"
df_2 <- df %>%
select(name, starts_with("h"))
df_2# A tibble: 5 × 3
name height hair_color
<chr> <int> <chr>
1 Luke Skywalker 172 blond
2 C-3PO 167 NA
3 R2-D2 96 NA
4 Darth Vader 202 none
5 Leia Organa 150 brown 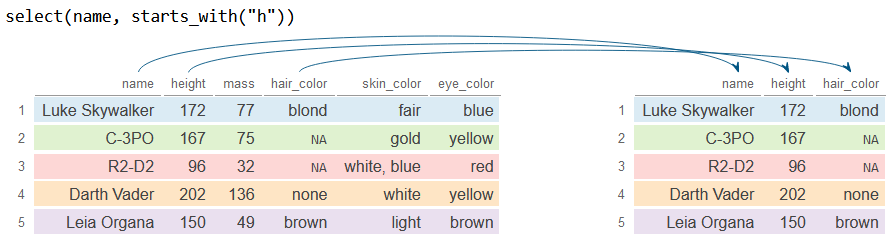
ends_with
De manera similar a la función anterior, ends_with busca las columnas que terminan con una cadena de texto específica. En el ejemplo anterior seleccionamos la primera variable (name) y todas las variables que terminan con "ss" (mass).
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Selecciona 'name' y las columnas que acaban en "ss"
df_2 <- df %>%
select(name, ends_with("ss"))
df_2# A tibble: 5 × 2
name mass
<chr> <dbl>
1 Luke Skywalker 77
2 C-3PO 75
3 R2-D2 32
4 Darth Vader 136
5 Leia Organa 49 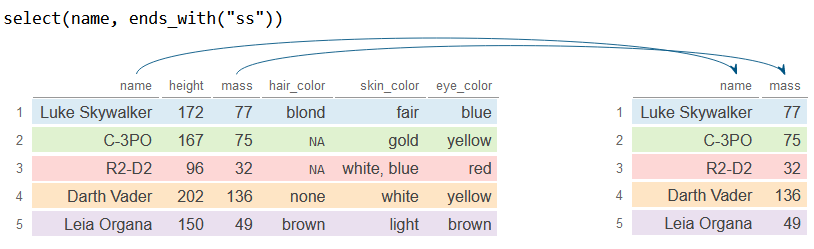
last_col
La función last_col selecciona la última variable del data frame. Ten en cuenta que esta función proporciona un argumento llamado offset que por defecto es 0 para seleccionar la enésima variable desde el final.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Última columna
df_2 <- df %>%
select(name, last_col())
df_2# A tibble: 5 × 2
name eye_color
<chr> <chr>
1 Luke Skywalker blue
2 C-3PO yellow
3 R2-D2 red
4 Darth Vader yellow
5 Leia Organa brown 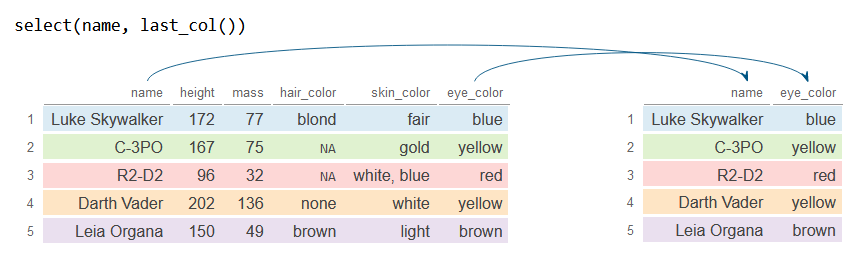
Usa !last_col() o -last_col() para seleccionar todas las columnas menos la última.
matches
La función matches selecciona columnas basándose en expresiones regulares. El siguiente bloque de código selecciona todas las columnas que contienen la letra a o la letra t.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Columnas que contienen la letra "a" o la letra "t"
df_2 <- df %>%
select(matches("a|t"))
df_2# A tibble: 5 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Luke Skywalker 172 77 blond
2 C-3PO 167 75 NA
3 R2-D2 96 32 NA
4 Darth Vader 202 136 none
5 Leia Organa 150 49 brown 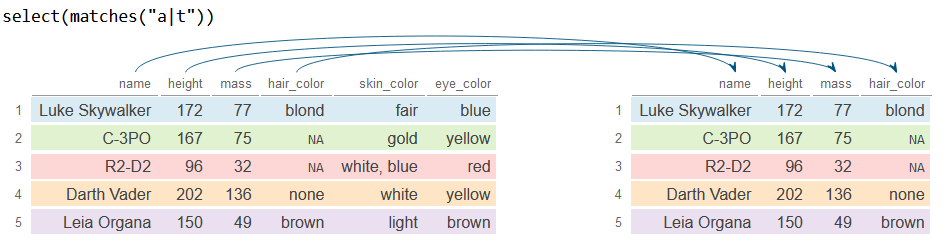
num_range
Si tus variables se nombran con un prefijo y un rango numérico, como x1, x2, … o y_1, y_2, …, puedes utilizar la función num_range para seleccionar rápidamente un rango de columnas.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Nuevos nombres de columna
colnames(df) <- paste0("x", 1:ncol(df))
# Selecciona x1, x2 y x3
df_2 <- df %>%
select(num_range("x", 1:3))
df_2# A tibble: 5 × 3
x1 x2 x3
<chr> <int> <dbl>
1 Luke Skywalker 172 77
2 C-3PO 167 75
3 R2-D2 96 32
4 Darth Vader 202 136
5 Leia Organa 150 49 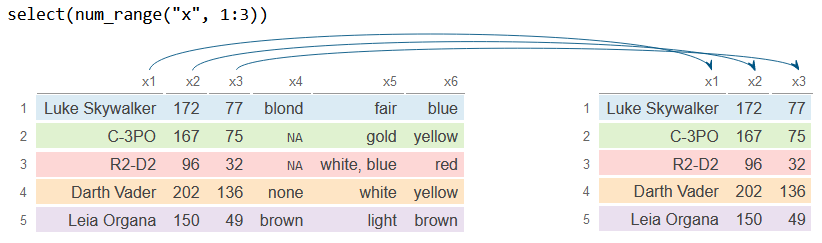
where
La función where toma una función que devuelve TRUE o FALSE como entrada y selecciona columnas basándose en la condición deseada. Por ejemplo, puedes seleccionar o eliminar todas las variables numéricas, de tipo carácter o que sean factores utilizando where(is.numeric), where(is.character) y where(is.factor), respectivamente.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
# Seleccionar todas las variables de tipo carácter
df_2 <- df %>%
select(where(is.character))
df_2# A tibble: 5 × 4
name hair_color skin_color eye_color
<chr> <chr> <chr> <chr>
1 Luke Skywalker blond fair blue
2 C-3PO NA gold yellow
3 R2-D2 NA white, blue red
4 Darth Vader none white yellow
5 Leia Organa brown light brown 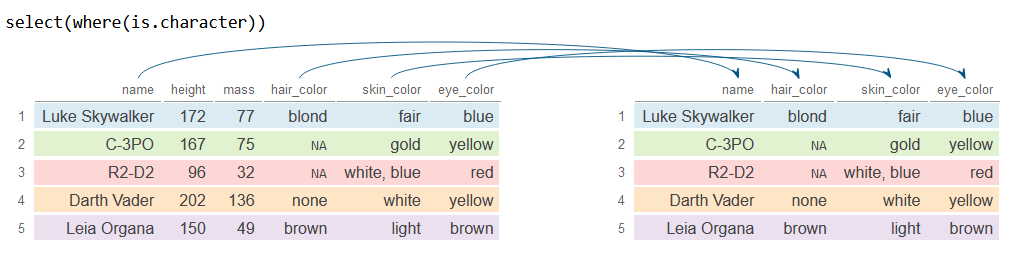
group_cols
La función group_cols selecciona las columnas agrupadas previamente con group_by.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
df_2 <- df %>%
group_by(name, eye_color) %>%
select(group_cols())
df_2# A tibble: 5 × 2
# Groups: name, eye_color [5]
name eye_color
<chr> <chr>
1 Luke Skywalker blue
2 C-3PO yellow
3 R2-D2 red
4 Darth Vader yellow
5 Leia Organa brown 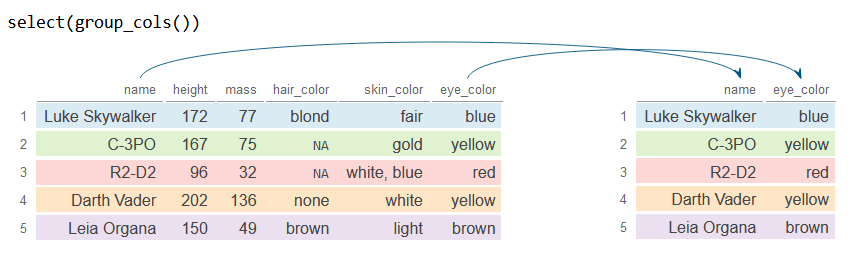
everything
La función everything permite seleccionar todas las columnas. Esta función es especialmente útil cuando se combina con otras funciones de dplyr.
# install.packages("dplyr")
library(dplyr)
# Datos de ejemplo
df <- starwars[1:5, 1:6]
df_2 <- df %>%
select(everything())
df_2# A tibble: 5 × 6
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Luke Skywalker 172 77 blond fair blue
2 C-3PO 167 75 NA gold yellow
3 R2-D2 96 32 NA white, blue red
4 Darth Vader 202 136 none white yellow
5 Leia Organa 150 49 brown light brown 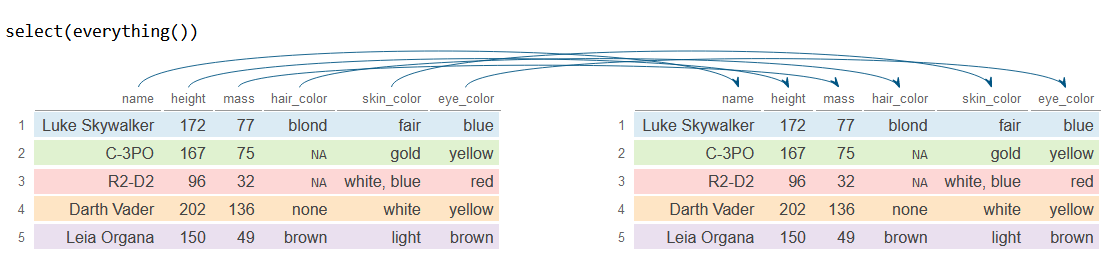
Puedes seleccionar la intersección o unión de dos conjuntos de variables con & y |. Por ejemplo, select(starts_with("h") & ends_with("r")) selecciona todas las columnas que empiezan por la letra h y acaban por r.